谷歌提出强化学习新算法SimPLe,模拟策略学习效率提高2倍
导读:谷歌最近提出一种新的强化学习算法:模拟策略学习 (SimPLe) ,使用游戏模型来学习选择动作的策略,在两款Atari游戏中获得了最高分数,并且效率比以前的最先进方法高出2倍以上。

谷歌最近提出一种新的强化学习算法:模拟策略学习 (SimPLe) ,使用游戏模型来学习选择动作的策略,在两款Atari游戏中获得了最高分数,并且效率比以前的最先进方法高出2倍以上。
深度强化学习 (RL) 技术可用于从视觉输入中学习复杂任务的策略,并已成功地应用于经典的 Atari 2600 游戏。最近在这一领域的工作表明,即使在具有挑战性的探索体系中,例如《蒙特祖玛的复仇》游戏,AI 也可以获得超越人类的表现。
然而,许多最先进的方法都有的一个限制是,它们需要与游戏环境进行大量的交互,通常比人类学习如何玩好游戏所需要的交互要多得多。
为什么人类能更有效地学习这些任务?一个可能的假设是,他们能够预测自己行为的影响,从而隐式地学习了一个关于哪些动作序列将导致理想结果的模型。
这种一般性的想法 —— 构建一个所谓的游戏模型,并使用它来学习选择行动的良好策略—— 是基于模型的强化学习 (model-based reinforcement learning, MBRL) 的主要前提。
Google 的研究人员最近提出一种新的 MBRL 算法 —— 模拟策略学习 (Simulated Policy Learning, SimPLe) ,使用游戏模型来学习选择动作的质量策略。
SimPLe 比当前最先进的技术更高效,并且仅使用了 ~100K 与游戏的交互即可显示出有竞争力的结果 (相当于一个人约 2 小时的实时玩游戏)。
研究人员在论文 “Model-Based Reinforcement Learning for Atari” 中描述了该算法,并已将代码作为 tensor2tensor 开源库的一部分开源。该版本包含一个预训练的世界模型,可以使用简单的命令行运行,并且可以使用类似于 Atari 的界面播放。
学习一个 SimPLe 世界模型
SimPLe 背后的想法是在学习游戏行为的世界模型和在模拟游戏环境中使用该模型优化策略 (使用 model-free 强化学习) 之间进行交替。该算法的基本原理已经在 Sutton 的“Dyna, an integrated architecture for learning, planning, and reacting” 中很好地建立起来,并且已经应用到许多最近的基于模型的强化学习方法中。

SimPLe 的主循环。1) agent 开始与真实环境交互。2) 收集的观测结果用于更新当前的世界模型。3) agent 通过学习世界模型更新策略。
为了训练一个玩 Atari 游戏的模型,我们首先需要在像素空间中生成合理的未来版本。换句话说,我们通过将一系列已经观察到的帧和给到游戏的命令 (如 “左”、“右” 等) 作为输入,来试图预测下一帧会是什么样子。在观察空间中训练一个世界模型的一个重要原因在于,它实际上是一种自我监督的形式,在我们的例子中,观察 (像素) 形成了一个密集且丰富的监督信号。
如果成功地训练了这样一个模型 (如一个视频预测器),则基本上有了一个游戏环境的学习模拟器 (learned simulator),可用于生成用来训练良好策略的轨迹,即选择一系列使智能体的长期奖励最大化的动作。
换句话说,我们不是在真实游戏的操作序列上训练策略,这在实践和计算上都非常密集,而是在来自世界模型 / 学习模拟器的序列之上训练策略。
我们的世界模型是一个前馈卷积网络,它接收 4 个帧,并预测下一帧以及奖励 (见上图)。然而,在 Atari 游戏的情况下,只考虑 4 帧的视界的话,未来是非确定性的。例如,游戏中的暂停时间就已经超过四帧,比如在《乒乓球》(Pong) 游戏中,当球掉出框时,可能会导致模型无法成功预测后续的帧。我们使用一种新的视频模型架构来处理诸如此类的随机性问题,在这种情况下能做得更好。

当 SimPle 模型应用于《成龙踢馆》(Kung Fu Master) 游戏时,可以看到一个由随机性引起的问题的例子。在动画中,左边是模型的输出,中间是 groundtruth,右边是两者之间的像素差异。在这里,模型的预测由于产生了不同数量的对手而偏离了真实游戏。
在每次迭代中,在训练好世界模型之后,我们使用这个 learned simulator 来生成用于使用近似策略优化 (PPO) 算法改进游戏策略的 rollouts(即动作、观察和结果的样本序列)。
SimPLe 工作的一个重要细节是,rollouts 的采样是从实际数据集帧开始的。由于预测错误通常会随着时间的推移而增加,使长期预测变得非常困难,因此 SimPLe 只使用中等长度的 rollouts。幸运的是,PPO 算法也可以从其内部价值函数中学习动作和奖励之间的长期影响,因此有限长度的 rollouts 对于像《Freeway》这样奖励稀疏的游戏来说也是足够的。
SimPLe 的效率:比其他方法高2倍以上
衡量成功的一个标准是证明该模型是高效的。为此,我们在与环境进行了 100K 次交互之后,评估了我们的策略输出,这相当于一个人玩了大约两个小时的实时游戏。
我们将SimPLe 方法与两种最先进的 model-free RL 方法:Rainbow 和 PPO,进行了比较。在大多数情况下,SimPLe 方法的采样效率比其他方法高出两倍以上。
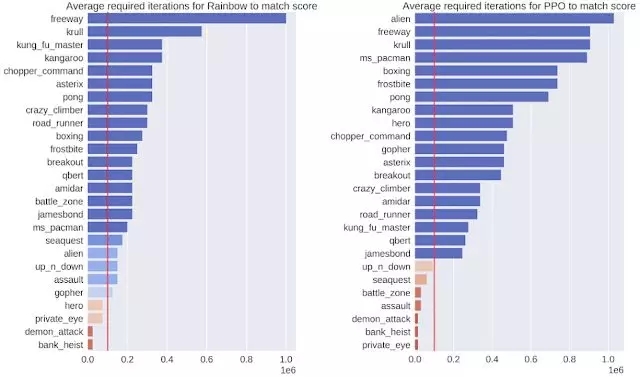
和我们 SimPLe 方法取得的得分匹配的话,两种 model-free 算法所需的交互次数(左 - Rainbow; 右 -PPO)。红线表示我们的方法使用的交互次数。
SimPLe 的成功:2款游戏获得最高分
SimPLe 方法的一个令人兴奋的结果是,对于 Pong 和 Freeway 这两款游戏,在模拟环境中训练的智能体能够获得最高分数。下面是智能体使用为 Pong 游戏学习的模型玩游戏的视频:

对于 Freeway、 Pong 和 Breakout 这 3 款游戏,SimPLe 可以生成 50 步以内的近乎完美的像素预测,如下图所示。
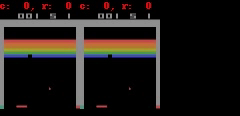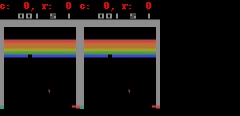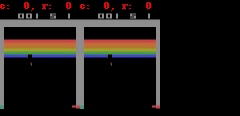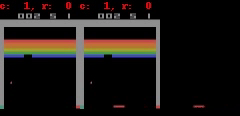
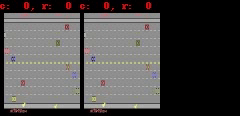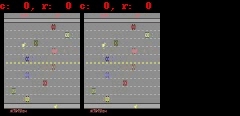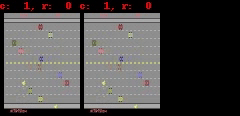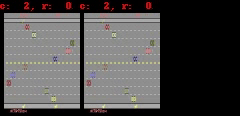
SimPLe 可以在 Breakout(上图) 和 Freeway(下图) 生成几乎完美的像素预测。在每个动画中,左边是模型的输出,中间是 groundtruth,右边是两者之间的像素差异。
SimPLe 的局限
SimPLe 的预测并不总是正确的。最常见的失败是由于世界模型没有准确地捕获或预测小但高度相关的对象。
例如:(1) 在《Atlantis》和《Battlezone》游戏中,子弹是如此之小,以至于它们往往会消失不见;(2)《Private Eye》游戏中, agent 穿越不同的场景,从一个场景传送到另一个场景。我们发现,我们的模型通常很难捕捉到如此巨大的全局变化。
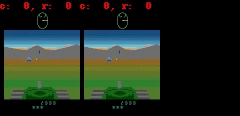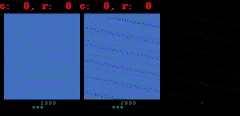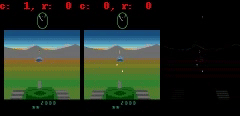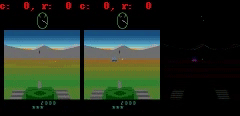
在《Battlezone》中,我们发现模型很难预测小但高度相关的部分,比如子弹。
结论
model-based 的强化学习方法的主要前景是在交互要么成本高昂、速度缓慢,要么需要人工标记的环境中,比如许多机器人任务。在这样的环境中,一个 learned simulator 能够更好地理解智能体的环境,并能够为执行多任务强化学习提供新的、更好、更快的方法。
虽然 SimPLe 还没有达到标准的 model-free RL 方法的性能,但它的效率要高很多。我们期望未来的工作能够进一步提高 model-based 的技术的性能。