图灵奖授予“深度学习三巨头”!他们拯救了AI、改变了世界
导读:27日,计算机领域最高奖项“图灵奖”迎来了新一届得主——加拿大蒙特利尔大学教授约书亚·本希奥(Yoshua Bengio)、谷歌副总裁兼多伦多大学名誉教授杰弗里·欣顿(Geoffrey Hinton),以及纽约大学教授兼 Facebook 首席 AI 科学家杨立昆(Yann LeCun)。

27日,计算机领域最高奖项“图灵奖”迎来了新一届得主——加拿大蒙特利尔大学教授约书亚·本希奥(Yoshua Bengio)、谷歌副总裁兼多伦多大学名誉教授杰弗里·欣顿(Geoffrey Hinton),以及纽约大学教授兼 Facebook 首席 AI 科学家杨立昆(Yann LeCun)。
这三位被业内人士称为“当代人工智能教父”的科学家是深度神经网络(deep neural network)的开创者,这项技术已经成为计算科学的关键部分,为深度学习(deep learning)算法的发展和应用奠定了基础——这正是现在计算机视觉(Computer Vison)、语音识别(Speech Recognizing)、自然语言处理(Natural Language Processing)和机器人研发等领域展现出惊人活力、掀起科技创业热潮的重要原因。
图灵奖(ACM A.M. Turing Award)由美国计算机协会于 1966 年设立,专门奖励对计算机事业作出重要贡献的个人,有着“计算领域的诺贝尔奖”(Nobel Prize of Computing)的美誉。其名称源自计算机科学先驱、英国科学家、曼彻斯特大学教授艾伦·图灵(A.M. Turing),奖金高达 100 万美元,由谷歌公司提供赞助。图灵奖大部分情况下只颁给一位获奖人,两位或三位科学家同时获奖的情况较为少见。2000 年图灵奖得主、中国科学院院士姚期智是目前唯一一位获得该奖项的中国科学家。
2018 图灵奖得主

约书亚·本希奥(Yoshua Bengio),在加拿大麦吉尔大学取得计算机博士学位。现为加拿大蒙特利尔大学教授、加拿大数据定价中心主任(IVADO)、蒙特利尔学习算法研究中心(Mila)科学主任、加拿大先进研究院主任。同时,他与杨立昆一起担任加拿大先进研究院机器与大脑学习项目的主管。他创建了目前世界上最大的深度学习研究中心——蒙特利尔学习算法研究中心(MILA),使蒙特利尔成为世界上人工智能研究最为活跃的地区之一,引来大批公司和研究室入驻。

杰弗里·欣顿(Geoffery Hinton),在爱丁堡大学获得人工智能博士学位。现任谷歌副总裁、工程研究员、多伦多人工智能矢量研究所首席科学顾问、多伦多大学名誉教授。他是加拿大先进研究院神经计算和自适应项目(Neural Computation and Adaptive Perception Program)的创始人,还获得了包括加拿大最高荣誉勋章(Companion of the Order of Canada)、英国皇家学会成员、美国工程院外籍院士、人工智能国际联合会(IJCAI)杰出研究奖、IEEE詹姆斯·克拉克·麦克斯韦金奖(IEEE James Clerk Maxwell Gold Medal)等一系列荣誉。2017 年被彭博社(Bloomberg)评为改变全球商业格局的 50 人之一。

杨立昆(Yann LeCun),在法国皮埃尔和玛丽·居里大学获得计算机科学博士学位。现任纽约大学柯朗数学科学研究所 Silver 冠名教授、Facebook 公司人工智能首席科学家、副总裁。他获得了包括美国工程院院士、IEEE神经网络先锋奖(IEEE Neural Network Pioneer Award)等一系列荣誉。他还是纽约大学数据科学中心的创始人,与约书亚·本希奥一起担任加拿大先进研究院机器与大脑学习项目的主管。
人工智能在 20 世纪 50 年代成为了一门科学。那时研究者们乐观地认为,在自己有生之年就可以看到拥有人类智力水准的机器出现。然而,当时的算法和计算能力都无法承担重任,美好的希望就此破灭。一些怀疑论者甚至认为制造人工智能的企图在根本上就是一种自大。直至 21 世纪初,约书亚·本希奥、杰弗里·欣顿和杨立昆开创的深度神经网络技术使人们重燃希望。如今他们的想法却带来了重大的技术革新,他们的方法也无疑已经成为当今该领域研究中的主流范式。
下面这篇文章由本届图灵奖得主约书亚·本希奥亲自撰写,讲述了深度学习算法从最初不被同行看好的弱势项目,发展成为拯救人工智能、改变世界的热门技术的背后故事,带你了解现代人工智能产业的前世今生。
深度学习:人工智能的复兴
撰文 约书亚·本希奥
上个世纪 50 年代,计算机在西洋跳棋(checkers)上击败了人类,还可以解决代数题,在世间引起了巨大轰动。60 年代时,人们充满信心地认为科学家很快就可以通过硬件和软件用计算机模拟人脑,而且这种“人工智能”很快就能在任何任务上与人类匹敌。1967 年,麻省理工学院的马文·明斯基(Marvin Minsky)甚至宣称,人工智能问题将在一代人的时间内被彻底解决(明斯基教授于 2016 年 1 月去世)。
现在看来,人们当时的乐观情绪显然过于幼稚了。尽管软件工程师已经设计出了旨在帮助医生更好诊断疾病的软件,开发了用于识别图片内容的模仿人脑的网络模型,但是效果均不理想。早期的这些算法不够复杂,而且依赖的海量数据也是当时无法提供的。另一方面,人类智能十分复杂,要想近似地模拟人脑功能需要巨大的计算量,可当时的计算机实在太慢,无法胜任。
到 2005 年前后,科学界几乎已经没人还看好机器可以达到人类的智能水平。在那个时候,“人工智能”似乎都已经变成了科幻的代名词。科学家和作家们往往将 20 世纪 70 年代到 2005 年前后的这段时间称为“人工智能的冬天”——梦想幻灭的日子。
10 年之后,一切都不一样了。从 2005 年开始,人工智能的形式出现了巨大变革。这一切源于“深度学习”(deep learning)技术的出现,这一方法原本指的是从脑科学中汲取灵感以制造智能机器,但后来已经自成体系。近年来,深度学习已经成为了驱动人工智能领域发展的最主要力量,各大信息技术公司在这方面共掷下了数十亿美元的资金。
深度学习指的是用计算机模拟神经元网络,以此逐渐“学会”各种任务的过程,比如识别图像、理解语音甚或是自己做决策。这项技术的基础是所谓的“人工神经网络”,它是现代人工智能的核心元素。人工神经网络和真实的大脑神经元工作方式并不完全一致,事实上它的理论基础只是普通的数学原理。但是经过训练后的人工神经网络却可以完成很多任务,比如识别照片中的人物和物体,或是在几种主要语言之间互相翻译等等。
深度学习技术彻底改变了人工智能研究的面貌,让计算机视觉、语音识别、自然语言处理和机器人领域重新焕发生机。2011 年,首个语音识别产品面世,也就是大家非常熟悉的 Siri。不久之后,用于识别图像内容的应用也成熟了起来,该功能现已被整合进了 Google Photos 的图片搜索引擎。
如果你嫌手机菜单操作起来太麻烦,那你一定会喜欢 Siri 或是其他智能手机助手给你带来的使用体验的飞跃。假如你对于几年前的图像识别软件还有印象,那你一定记得当时的识别效果相当糟糕,有时甚至会误把吸尘器认作犰狳。而现在这个领域早已发生了翻天覆地的变化,现在的软件在某些情况下识别出猫、石头或人脸的准确率甚至和人类相当。人工智能软件如今已成为了数百万智能手机的标配,拿我自己来说,我已经很少用手输入信息了,都是直接对手机说话,有时它也直接用语音回应我。
这些技术进步一下子为进一步的商业化打开了大门,人们对人工智能的热情日益高涨。各大公司竞相招揽人才,擅长深度学习的博士一下子变成了供不应求的稀缺商品。这个领域的很多大学教授(可能是绝大多数)都已经从象牙塔被拉到了产业界,企业为他们提供了一流的研究环境与设施,以及优良的待遇。
在利用深度学习解决各种问题的过程中,科学家们取得了惊人的成就。2016 年 3 月,神经网络模型 AlphaGo 击败了世界顶级围棋选手李世石的新闻占据了各大媒体的首页(编者按:这篇文章发表一年后,AlphaGo 和世界围棋冠军柯洁的对战再一次掀起了媒体的报道狂潮)。机器在其他领域超越人类的步伐也在加快,而且不局限于竞技游戏。最新的深度学习算法可以从磁共振图像中准确检测出心脏是否衰竭,准确度甚至能和心脏病专家媲美。
智能、知识、学习
人工智能为什么在之前的几十年会遇到这么多挫折呢?因为对机器来说,学习新事物是很难的。编写计算机程序需要把任务用很规范的方式写成一条条具体的规则,但世界上大部分知识并不是这样的形式,所以我们很难直接给电脑编写程序,让它实现人类可以轻而易举完成的任务,例如理解语音、图像、文字或是驾驶汽车等。科学家之前尝试过直接编程,将复杂的数据集按照某些规则进行细致的分类,希望以此让计算机渐渐拥有类似“智能”的东西,可是这种尝试并无建树。
但是深度学习突破了这个困境。深度学习属于人工智能领域内一个更宽泛的概念——机器学习,即根据某些基本原理训练一个智能计算系统,最终使机器具备自学的能力。其中一条基本原理,就涉及到人或者机器如何判断一个决策是好是坏。对动物来说这就是演化原理,“好”的决策意味着提高存活和繁衍几率;在人类社会中,“好”决策可能是指提高地位或产生舒适感的社会活动;对机器而言,以智能汽车为例,一个决策的“好坏”则可能被定义为其行驶模式在多大程度上接近优秀的人类司机。
在特定情况下做出好决策所需的知识并不一定能轻易地用计算机代码表示出来。比如说一只小鼠,它会熟悉自身周围的环境,而且本能地知道该去嗅哪里,该如何移动四肢,该怎样寻找食物或配偶,并避开天敌。但没有哪位程序员可以用一行一行的代码写出一个能做出这些行为的程序,虽然这些行为所需要的知识都存储在小鼠脑内。
在让电脑学会自学之前,计算机科学家必须搞清楚一些基本问题,比如人类是如何获取知识的?人类的知识部分是天生的,但大部分都是从经验中学习而来。自上个世纪 50 年代以来,科学家就一直在寻找动物和人类(或是机器)从经验中学习知识的基本原理。机器学习的研究致力于建立一系列所谓“学习算法”的流程,可以让机器从样例中学习。
机器学习在很大程度上算是一门实验科学,因为还没有普适的学习算法出现,对于不同的任务,科学家需要开发不同的学习算法。每个学习知识的算法都需要在相应的情况下,用相应的任务和数据进行测试,有时候任务是识别一副图像是不是日落,有时候任务是把英语翻译成乌尔都语。我们没法证明一个算法可以在任何任务中都比别的算法表现更好。
人工智能专家用正式的数学语言描述了这个原理——“免费午餐”定理。这个定理指出,不存在可以解决所有实际问题的“万能”机器学习算法。可是人类的行为似乎违背了这个定理:我们的大脑中似乎存在一些通用的学习算法,能让我们学会各种任务。要知道,这并不能完全归结于演化,因为很多任务我们的祖先都没有做过,比如下棋、建造桥梁,或者是研究人工智能。
这说明,人类智能利用了关于世界的一般性假设,启发科学家创造出具有通用智能的机器。正因如此,科学家以大脑为模仿对象,开发出了人工神经网络。
大脑的计算单元是一些叫做神经元的细胞,每个神经元可以通过叫做突触间隙的小缝隙向其他神经元发放信号,神经元跨越间隙传输信号的效率叫做突触强度(synaptic strength)。在神经元“学习”的过程中,它的突触强度会增加,也就是说当它受到电信号的刺激时,它更有可能向邻近神经元传输信号。
受脑科学的启发,计算机科学家开发出了人工神经网络,用软件或硬件实现了虚拟神经元。人工神经网络是人工智能领域的一个分支,该领域在早期又被称为“联结主义”(connectionism)。计算机科学家认为,神经网络可以接收视觉或听觉输入,渐渐改变神经元之间的连接强度,最终网络连接会形成一种特定模式,让神经元的电信号可以提取出图像内容或是对话短语的特征,从而实现一些复杂的任务。随着人工神经网络接收的样例越来越多,学习算法不断调整神经元连接的突触强度,可以更准确地对输入数据(如日落的图像)进行表征。
给自己上一课
最新一代的神经网络则在“联结主义”的基础上更进一步。在神经网络中,每个突触连接的强度都由一个数值决定,代表了这个神经元向其他神经元传递信号的可能性。以图像识别为例,每当网络接收一幅新图像时,深度学习算法就根据当前输入对连接强度做一点小调整。随着见过的图像越来越多,网络连接强度就会一点一点地变为最优连接模式,使网络预测图像内容的准确度不断提高。
为了得到最好的结果,目前的学习算法仍然需要人的密切参与。大部分算法均使用了叫做“监督学习”(supervised learning)的技术,这是指在训练过程中,每个训练样本都配有一个与内容相关的标签,比如对一幅日落的图像,同时还会附上标注“日落”。监督学习算法要做的,就是让网络以这幅图像作为输入,并输出图像中央的物体名称。在数学上,把输入变成输出的过程叫做函数(function)。机器学习的目标就是找到可以实现学习任务的函数所对应的参数,比如突触连接强度。
用死记硬背的方式来记住正确答案固然直截了当,但也毫无意义。机器学习的终极目标是让算法明白“日落”到底指的是什么,然后可以认出任何一幅日落的图像,不管这幅图在训练过程中有没有出现过。
要获得能够识别出任何日落图像的能力,也就是所谓的从具体示例中进行概括并推广的能力,这才是所有机器学习算法的主要目标。事实上,科学家评价网络的学习效果时,就是用该网络从未见过的图像来测试其识别准确率。由于在每一类别下面都有无穷多种变体,要想识别从未见过的图片并非易事。
想让深度学习算法从大量样例中概括出抽象的概念,除了输入样例以外还需要其他信息,比如一些关于数据的额外假设,或是对特定问题而言最优解大概该是什么形式的猜想。具体来说,图像识别软件中常用的假设之一,就是当给特定网络输入相似的图片时,网络的输出也不该有太大变化。比如把一张猫的图像中的某几个像素进行改动,那么图像依然是猫而不会变成狗。
有一类基于这些假设的神经网络叫做“卷积神经网络”(convolutional neural network),正是这项关键技术推动了人工智能的复兴。深度学习中的卷积神经网络包含很多层神经元,层与层之间通过特定的方式连接,使得输出结果对图像中央物体的变化(例如位置稍稍偏移)不会非常敏感,这样的网络在训练完成后可以认出从不同角度拍摄的人脸。卷积神经网络的设计灵感源自人脑视觉皮层的层状结构,它在人脑中负责处理从眼睛接收的图像信号。卷积网络中包含很多层虚拟神经元,“深度”学习的“深”指的就是这个。这类网络涉及到的计算量十分巨大,但是它可以学会很多任务。
深度学习
从实践角度看,大概是10年前出现的一些研究进展,让深度学习从一些技术创新中脱颖而出。当时的人工智能领域正跌入几十年来的最低点,但一个由政府和私人资助者支持的加拿大组织重燃了科学家的研究热情。这个名为加拿大高等研究所(Canadian Institute for Advanced Research,简称 CIFAR)的组织资助了由多伦多大学的杰弗里·欣顿(Geoffrey Hinton)领导的一项计划,计划参与者还包括纽约大学的杨立昆(Yann LeCun)、斯坦福大学的吴恩达(Andrew Ng)、加利福尼亚大学伯克利分校的布鲁诺·奥尔斯豪森(Bruno Olshausen)、本文作者本希奥以及其他一些科学家。当时这个研究方向并不被世人看好,导致相关工作很难发表,研究生们也不愿意在这个方向发展。但是我们中的一小部分人还是有强烈的预感:这是一条正确的道路。
人工智能之所以在当时不受待见,部分原因是科学家普遍认为训练好一个神经网络几乎是不可能的,很难找到可以高效地优化网络以提升其性能的学习方法。“最优化理论”(optimization)是数学的一门分支,它所做的事是尝试找到能达到一个给定数学目标的参数组合,而在神经网络中,这些参数被称作“突触权重”(synaptic weight),反映了信号从一个神经元通向另一个神经元的强度。
深度学习的最终目标是做出准确的预测,也就是将误差控制在最小的范围内。当参数与目标之间的关系足够简单时——更确切地说,目标是参数的“凸函数”(convex function)时,可以逐步对参数进行调整,直到接近最优解(或称“全局最小点”),即整个网络的平均预测误差最小时。
然而,神经网络的训练过程并不简单,需要另一种“非凸优化”(nonconvex optimization)过程。非凸优化就更麻烦了,很多研究者甚至认为这一障碍是不可克服的。学习算法在运算过程中可能会陷入所谓的“局部最小点”处,此时,轻微调整参数值就无法减小预测误差,也就无法进一步提升模型性能了。
科学家一直觉得神经网络难以训练的罪魁祸首是局部最小点,这个误解直到 2015 年才得到澄清。本文作者在研究中发现,当神经网络足够大时,局部最小点造成的麻烦会小很多。对于一个稳定的网络,大部分局部最小点都反映了模型已学到的一定程度的知识,而且几乎和全局最小点处的情况一致。
即使知道最优化问题在理论上是可解的,研究者在训练包含两三层以上的神经元网络时依然常常失败,当时很多人认为继续这类研究毫无希望。从 2005 年开始,由 CIFAR 支持的一些工作不断取得突破,成功解决了这个问题。2006 年时,我们找到了训练深层网络的算法,所用到的技巧就是逐层训练。
后来,在 2011 年我们又发现,只要改变一下每个虚拟神经元的运算,让它们表现得更像真实的神经元,就可以训练包含更多层神经元的深层网络。我们还发现,在训练过程中给网络中传输的信号上加上噪音,也可以让网络更好地识别图像或声音,这一点也类似于大脑中的信息处理流程。
深度学习技术的成功依赖于两个关键因素。首先是计算速度的大幅提升:科学家借用了本为电子游戏所设计的图形处理器(GPU),使计算速度提升了 10 倍,这使得在有限的时间内训练大规模网络变为可能。让深度学习研究开展得如火如荼的第二个因素是海量带标记数据集的出现,这些数据集内的所有样例都配有正确的标记——如一幅图中有猫这个元素,便会被标上“猫”。
深度学习近年来的成功还有一个原因:它可以通过学习算法找到一系列运算操作,对一幅图像、一段音频或是其他信号进行逐步的重构或分析,这里的步数,就代表着网络的深度。目前人工智能可以高效地处理很多视觉或听觉识别任务,都要求网络的深度足够大。事实上,最近的理论和实验的相关研究表明,假如网络深度太浅,是无法完成这些复杂的数学运算的。
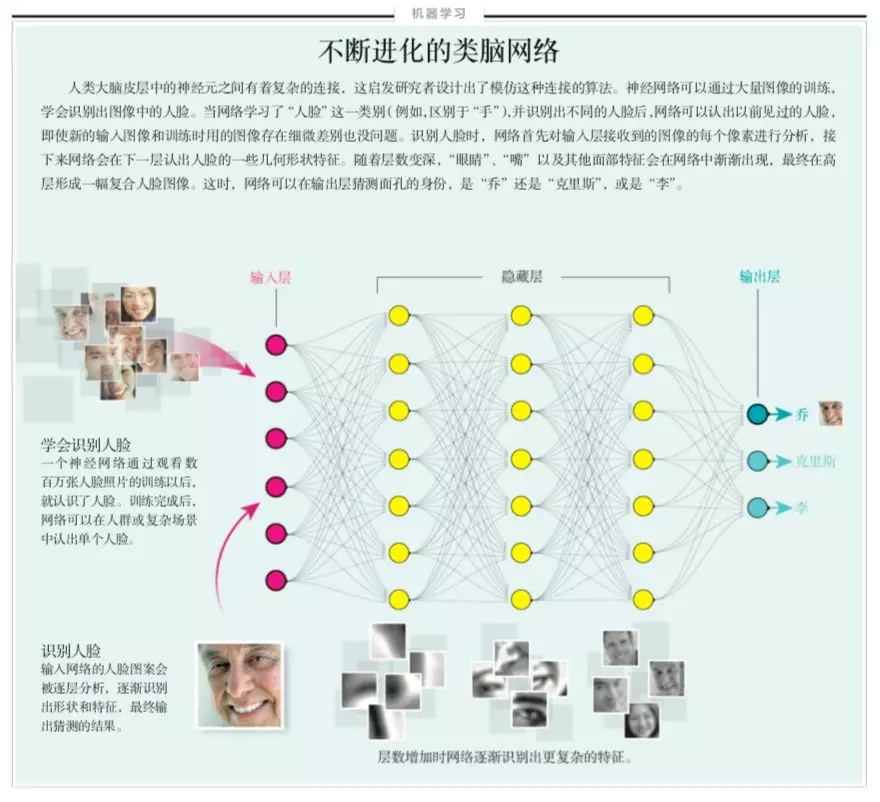
深层神经网络中的每一层把接收的输入进行处理,再把输出传向下一层。越到深层,其所表征的概念就越抽象,因为这些层离最初的输入信息距离太远(见图文框“不断进化的类脑网络”)。实验发现,深层的虚拟神经元往往对应了一些抽象的语义概念,比如代表了“桌子”的图像。即使在训练过程中网络从来没有看到过单独被标注有“桌子”的样例,一些深层虚拟神经元在处理信息时依然可以认出对应着桌子的图像。而且“桌子”这个概念还可以作为中间步骤,在更深的神经元层中产生更抽象的概念,比如“办公室场景”。
模式识别之外
直到不久前,神经网络的成功还大部分局限在识别静态图像方面,但是也有一些神经网络擅长处理随着时间变化的任务。以递归神经网络(recurrent neural network)为例,这种网络可以连续执行一系列运算,处理语音、视频或其他数据。时序数据由一个个单元(不管是音素还是词语)依序排列形成,递归神经网络处理这些输入信息的方式也和大脑的工作模式相似:当大脑在处理感官输入的信号时,神经元传递的信号也不断变化。大脑内的这种神经状态会把输入信号视作周围环境中发生的各种事件,进而输出合适的指令,告诉身体该如何行动以达成特定目标。
递归神经网络可以预测一句话中的下一个词是什么,由此产生连续的词语序列。它们也可以完成更复杂的任务:在“读”完整个句子之后,猜测出句子的意思。然后再使用另一个递归神经网络,就可以利用前一个网络做完的语义分析,把句子翻译成另一种语言。
递归神经网络研究在上世纪 90 年代末到本世纪初也经历过低潮。本文作者的理论工作表明,这种网络在处理时序信息时,很难回忆起太久之前的输入,即输入序列中最早的那部分。想象一下当你读完一本书时,是否还能逐字逐句回忆起书的开头?但后来的几项技术创新在部分程度上解决了这个问题,使网络的记忆能力得到显著提升。现在,神经网络会在电脑中留出一块额外的临时存储空间,专门处理分散的多段信息,例如分散在一个长文档中的各种句子的含义。
在经历了人工智能的寒冬之后,深度学习神经网络的强势回归不仅仅代表着技术上的胜利,也给整个科学领域上了一课。回顾人工智能的历史,我们必须意识到,哪怕一些好的想法受到当时的技术状态限制而看似前景渺茫,我们也不应放弃。鼓励多样化的科研课题与方向,或许有一天就会让一时处于低谷的领域迎来复兴。