郭毅可:踏踏实实地研究人工智能
导读:今天人工智能的巨大成就表现在机器学习上取得了突破性的发展及“智能+”推动了人工智能的普适应用。人工智能成为世界科技发展的一个新高地,各国对此都作出战略布局。
今天人工智能的巨大成就表现在机器学习上取得了突破性的发展及“智能+”推动了人工智能的普适应用。人工智能成为世界科技发展的一个新高地,各国对此都作出战略布局。同时,人工智能的发展也向我们提出了新的挑战,在伦理、社会治理等方面引入了新的课题。在展望人工智能光明前景的同时,我们也要清楚地认识到:人工智能,特别是机器学习,它基本的方法、基本的思路还是比较简单和粗糙的。现在的人工智能是着重于智能外延的人工智能,也就是说着重于模拟人的智能的外在功能,而人工智能的发展还有待于在智能内涵的理解上的不断进展。本文就此对人工智能的发展作一个抛砖引玉的讨论, 也对机器学习的研究方向作探讨。
撰文| 郭毅可
(上海大学 计算机学院,上海 200444;英国帝国理工学院 数据科学研究所,英国 伦敦 SW7 2AZ)
2018年中关村峰会邀请我作报告,我把发言题目定为《踏踏实实地研究人工智能》。取这个题目,我当时有点忐忑,因为《踏踏实实地研究人工智能》这个题目好像是说我对今天人工智能的发展有一定的看法。可就在这时,我读到了习总书记的一个讲话,他说要进一步推动我国新一代人工智能的健康发展。我认为总书记说的“健康”非常重要,“踏踏实实”实际上是健康发展的一个重要的部分。所以,我很高兴就这个问题发表一下我的看法。
大家都知道,人工智能风起云涌,中国和美国是两大人工智能的主要战场。美国有2 000多个AI 公司,中国也有1 000多,发展都很快。从投资角度来说,我们可以看到,投资量不断增长,中国的投资量还高于美国。可是中国对AI的投资在2018年有一个拐点,就是人工智能的投资增长的速度降下来了。为什么呢?因为大家注意到我们有些浮躁了。浮躁在哪里?一是表现在对人工智能技术理解的片面性和不合现实的期望;二是表现在对人工智能技术应用的简单化;三是表现在对人工智能技术对社会发展的影响和作用的神化或妖魔化。
人工智能是人类用机械解放了自己的体力之后,希望通过计算机来解放自己的脑力的努力。所以,人工智能是计算机科学发展的初心。我们讲到的人工智能,实际上有三个重要的部分。
第一个部分是模仿我们的感知。感知的意义范围很广,主要意思是指通过感觉器官对外部世界在人脑中获得的有意义的印象,而机器的感知就是通过作为机器感觉的器官,即传感器,获得外部世界的信息,并建立对它的理解。
第二部分是模仿我们的认知,即模仿人们获得知识的过程。图灵奖获得者赫伯特•西蒙认为,人的认知有3种基本过程:①问题求解,即在已有知识的基础上,通过分析、推理等思维过程来解决问题;②模式识别能力,即建立对事物的抽象,包括对事物特征元素的把握、对各元素之间关系的建立,并根据元素之间的关系构成模式,形成抽象;③学习,就是把获取的感知信息通过模式识别,以及与已有的知识联系得到新的知识,并把它们的组织贮存起来。模仿这样的认知过程是今天人工智能研究的主要内容:机器推理是问题求解的基本技术;模式识别是机器学习的一个关键领域,而对人类学习的模仿包括了机器学习(知识的获取)、知识表达、知识库的全部研究。
最后,人脑通过感知获得外界输入的信息,经过头脑的认知,转换成内在的心理活动,进而支配人的行为对环境作出改变,那就是第三部分——决策。这里对环境作出改变应该是有一个目标的,且这样的目标应该是有益的。为了达到目标,也要继续学习以获取知识,这样在决策过程中的不断学习正是强化学习的场景。
我们也知道,这几年深度学习发展很快。深度学习是知识获取的一种形式。如图1所示,横轴是时间轴,纵轴是计算量,随着时间的推移,我们的数据量和计算能力在不断增长,这导致我们获取知识的能力也越来越强。开始时是从手工获取知识,像20世纪70、80年代做的专家系统。把专家知识编码成规则输入到计算机中,这样的知识获取方法既受到我们自己知识内容的限制,也受到对知识编码形式的限制。所以,专家系统的发展到80年代后期就停滞了,取而代之的很多研究就在于机器自动获得知识的方法。开始我们把它叫作数据挖掘,而后又称为知识发现,今天又把它称之为机器学习。机器学习的目标在于完全自动化进行知识获取。深度学习就是这样一种方法,它用到大量的数据和算力。深度学习的算法早就有了,今天的技术,包括大量的数据和强大的算力,使得它有了普遍使用的可能。
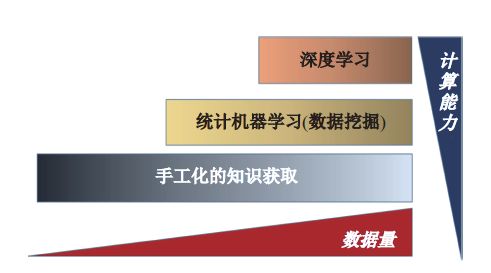
图1 知识获取途径的变化:从手工化的知识获取到深度学习
现在我们来看人工智能,特别是机器学习,虽然有很大的发展,但是也应该非常客观地看到,它基本的方法、基本的思路还是比较原始、比较简单的。那么,现在的人工智能,用我的观点来说是着重于智能外延的人工智能,也就是说着重于模拟人的智能的外在功能,而模拟的方法基本上是以统计为基本原理的。今天的机器学习,无论是什么方法,基本的思路都是给出一大堆数据作为学习样本,然后寻找一个函数来拟合数据,这个函数就代表了对于数据反映的世界的模型和抽象。所谓的深度学习是说这样的函数比较复杂,我们用复杂的非线性函数来拟合样本。我们可以对机器学习作一个简单的描述:我们需要足够大的样本,再搜索一个最好的函数来拟合样本。这样的最好是局部化的,是局部最优。所有的机器学习都是一个优化过程,所有的学习都是给出一个拟合目标,然后根据数据学习一个函数,来最好地接近这个目标。所有的学习做的都是搜索拟合最优化的过程。搜索的方法就是用梯度下降的方法,通过求导数来找到局部最优解的方向。
所以,可以用一句话讲清楚深度学习:我们现在的深度学习就是在足够的样本上用梯度下降的方法做出一个足够大的参数化模型,来拟合样本。
是不是人工智能就只是这样?当然不是!人工智能最重要,也是最困难的地方在于理解智能的机制。也就是说,不仅是拟合函数,还要理解知识的表达和知识的应用。知识的表达不仅包括概念本身的发现,也要发现概念之间的关系,知识图谱就是一个方法。人的一个非常大的智能行为就是抽象,譬如用一个方程描述自然现象,机器要做到这样非常困难。要研究机器的抽象能力。人的智能行为不仅仅是获取知识——这往往是感知的任务,而且人类智能的一个重要的能力在于知识融会贯通的应用, 而这样知识应用和知识获取往往又是分不开的。我们总是在知识的指导下来学习,来获取知识。这些机制在今天的机器学习中并没有很好的研究。我们还要研究人对于客观的反映形式,对于不确定性情况下的推理机制。这些都是着眼人工智能的内涵研究的课题,就是研究智能的基本机制。
当我们只注重智能外延研究的时候,它有非常大的局限。2011年图灵奖获得者朱迪亚•珀尔(Judea Pearl)教授曾经讲过一句话,“鹰和蛇的视觉系统都比我们在实验室能做的系统更好,但是鹰和蛇都不能做出眼镜、望远镜或者显微镜来。”
我们首先来谈谈知识,或者说常识,在机器学习中的重要性。图2是一个小孩含着一把牙刷。目前的深度学习模型可以生成对图的理解,但这个理解不知道一个小孩拿的是牙刷,因为学习模型时,没有牙刷这个样本。机器也不知道棒球棒不能放在嘴里的常识。这就是单纯的数据驱动来进行学习的一个很大的弱点。有一个很有意思的笑话:当有许多人不断去撞墙时,你问一个孩子“你会去撞吗?”, 那个孩子一定说“不”;而你问一个机器学习算法时,它的回答一定是“会!”。

图2 目前的深度学习可以生成对图的理解,但并不能理解常识
没有利用知识的学习就无法得到具有足够普遍性的知识,形成概念;而且模型对于数据的依赖也使得模型非常的不稳定。我们常常看到一些例子,在图像中引入一些小小的噪声就会破坏整个模型的识别结果,最后学习的结果,即模型,也无法解释,因此我们只能把识别过程作为一个黑箱来用。这显然是非常不合理的。试想,你愿意接受一个机器给你的诊断,而无法知道这个诊断的理由吗?所以,如何在学习中应用知识是一个重要的课题, 也是人工智能发展的必然方向。
今天的学习基本上是一个线性的过程(图3)。我们强调数据驱动, 强调“端到端”即从数据到知识(模型),没有人的参与。人的知识的输入仅仅是通过对数据的标注。
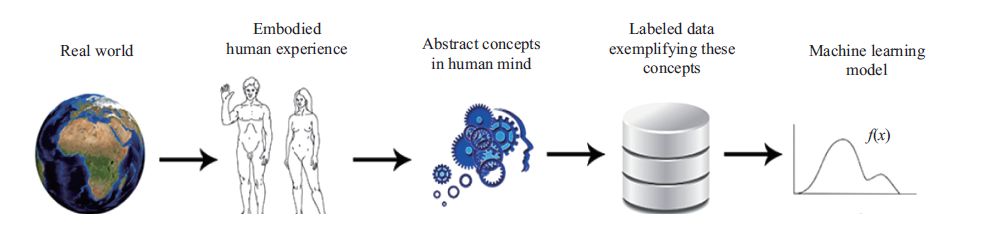
图3 数据驱动深度学习的线性过程
这样的学习模式的高度自动化带来的优越性并不能掩盖它缺乏知识应用的弱点。所以,在未来的机器学习中,这样“端到端”的学习将只是整个学习过程的一个局部模块中的学习方式, 而从全局来看,如图4所示,机器学习的过程将会是一个机器与机器、机器与人的一个交互环境,其中各种知识的交互、融合将是学习的一个重要特征。这里有机器把学到的知识应用到充满不确定性的现实世界中来进行推理,从而认识模型的性质,并对它不断地改进。这就是不确定性推理 (reasoning with uncertainty)的研究。我们学习的知识也应该是可解释的, 而可解释的关键是找到一个从机器模型空间到人的概念知识空间的映射。这样的映射的建立有赖于我们对知识表达和知识管理研究的重新认识和发展。我们称这样的研究为可解释的AI(Interpretable AI)。我们知道所有的机器学习都强调用数据来发现模型,可是有很多是模型已经知道的,比如说许多物理模型,都是我们知道的定理。这些模型怎么应用到机器学习当中去成为重要的先验知识,也很重要。今天的机器学习的统计学基础是贝叶斯理论。深度学习之父杰弗里•辛顿就认为研究大脑的最好方法,就是将它想象成一台贝叶斯概率机(Bayesian probability machine)。19世纪赫曼•冯•亥姆霍兹(Hermann von Helmholtz)在其工作中就曾提出过这一观点,认为大脑以概率的方式计算和感知世界,根据接收到的信息调整想法,进行预判。在最流行的现代贝叶斯模型中,大脑像个“推理引擎”,目的是最大限度减少“预测误差”。贝叶斯理论的精髓就是对先验知识的应用。我们称这样的学习为知识支持下的学习 (knowledge supported learning)。
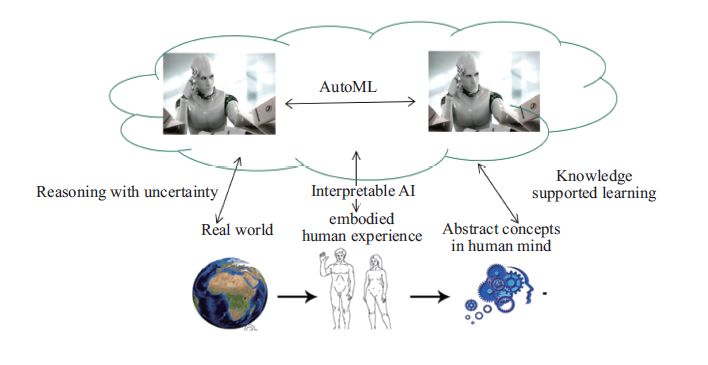
在经典的人工智能中,把先验知识融合到机器学习中的成功例子很多,诸如在机器人和自动驾驶中常用的卡尔曼滤波器和即时定位与地图构建技术(SLAM技术)都是这个方向上的杰出成果。这方面的工作也在工程模拟上有很大的应用,其中数据同化的理论和技术正是典型的一种知识支持的学习研究。近年来,英国科学家卡尔•弗里斯顿(Karl Friston)提出了自由能量原理,认为认知过程就是减少大脑期望状态与测量状态之差,即自由能量最小化。这里期望状态来自于我们脑中的知识,而测量状态就是我们感知的数据。这一理论的提出,实际上奠定了知识支持下学习的认知学基础。我们还要强调的是机器如何从经验学习。实际上人也是一样,我们往往从经验中获得知识,而不是从数据中。如何从经验中进行学习,机器和机器能够互相交流学习经验,这是非常重要的研究方向。现在AlphaGo下棋下得这么好,很重要的原因是用到了机器和机器对弈的概念,机器和机器之间进行相互学习,这是自动学习(AutoML)的思想。
虽然今天的人工智能技术还有很多局限,但在应用上还是有非常大的突破,同传翻译就是一个好例子。在现在的会议上,同传翻译翻译得很快,也很有意思。同传的知识理解往往不够,所以常常翻译得不对,但是基本上能给出一个大概的意思。这就是人工智能的现状,可用,但还不好用!
我们希望把知识融合进学习过程的未来机器学习做得更好。还是以同传翻译为例,就是说它翻译的时候能够理解报告人讲话的背景和整个上下文的关系,这就要用到在不确定情况下的推理,在不断变化观察中寻找因果关系。翻译中不但要翻译语言,还要进行推理和理解,使翻译更准确。现在有很多机器学习的工作是围绕知识的,比如怎么样实现零样本学习。当孩子看见一个物体,比如一只熊猫,他不需要很多样本,只要知道熊、猫的特点,知道有熊猫这个概念,即便他是第一次看到熊猫,也会推理出这个动物叫熊猫。机器有没有这个能力?没有。我们能不能通过实现这个机制使得学习更智慧?这就是零样本学习的思想。我们可以把动物的知识图谱融合到学习中,这样,在学习中就可以根据熊猫的特征,利用知识图谱进行“概念插值”,从知识图谱中推断出熊猫的分类来。知识支持下学习的另一个方向就是研究如何把学到的知识再用于学习。现在许多机器学习的技术,如转换学习、联邦学习等都是把学到的知识再用于学习的例子。
这样有知识的学习有广泛的应用价值。举一个简单的例子,我们做的工作是医学图像的识别,用机器来做图像分割,确定病区。这可以用深度学习做,需要大量的数据,但医学里面使用大量的数据不现实,数据很贵。那我们是否可以换一个思路?假定给出一个精度要求,我们探究是否可以用最少的数据做到。这意味着要对原来的数据作很多领域知识的理解。我们用到了医学图像中几何的知识,并把它用到标图之中,这样我们用十分之一的数据就能获得非常精准的图像分割。这就是有了知识以后学习的有效性。
最后,我想用几句话来总结一下本文的观点。我用毛主席的几句话:
第一句是“前途是光明的,道路是曲折的。”首先要看到虽然人工智能发展很快,但我们认识智能的道路很曲折,实际上我们仅在一些专用领域、专用功能上体现智能,离真正的智能水平相差很远,所以我们有很多工作要做。我们不要把现在的技术穷尽以后再做新的技术,要大大加强人工智能的基础研究。第二句是“百花齐放,百家争鸣。”人工智能是个交叉学科,我们必须坚持多学科的交叉,不要赶一种技术的时髦。把认知科学、脑科学、生理学、心理物理学、数学、统计学结合起来对智能进行研究会有很大的前景。第三句是“经济基础决定上层建筑。”我们不要忽略人工智能对社会的影响的研究,要充分看到人工智能对人类社会的发展在伦理、法律、治理各方面提出的新课题、新挑战,要认真研究,不然人工智能的发展就不会是可持续的。
我们在人工智能关键技术上不能有短板,要抓好算料、算力和算法这“三算之纲”!算力不仅是芯片,还包括平台、操作系统,这才是真正的人工智能核心技术。然后还有算料。大家都说中国的数据很多,但数据要有质量才能用来训练模型,有高精度的数据,才会有好的模型。这样的高质量数据还不多。我们不仅要搞“大数据”,还要搞“金数据”,把高质量的数据作为我们的国家资源,储备好,用好。区块链是数据资本化的关键技术,要在数据资本化场景下发展好这个技术。还有就是新的算法。不要人云亦云,亦步亦趋,唯马首是瞻,要大力提倡有思想性的创新。最后,人工智能对社会伦理的研究也十分重要。这都是在人工智能方面不能有的短板。
人工智能的发展取决于人才,我们培养的人工智能的人才不能是人工智能中的人工,而是智能的创造者。人工智能的科学家应该是具有哲学思想、数学抽象、物理理解、计算机实现等能力的认知科学家。同时,我们的人工智能工程师也需要和领域科学家相互结合,真正成为“智能+”的社会财富创造者。
最后,我用图灵一句话结束此文:“我们没有能力看得太远,我们却能看到在不远的将来,我们也有许多事要去做。”这就是说,我们一定要踏踏实实地把很多的关键科学技术问题研究好,不要认为人工智能已经完成了它的研究征程,没有,远远没有!人工智能的研究才刚刚开始,有许多事情要做,有许多事情可以做,有许多事情等待我们去创新。
(2019年3月10日收稿)■
本文刊载于《自然杂志》2019年第2期,转载请注明作者和来源。