人工智能行业策略报告:把握赋能、创新与安全三条主线
导读:从整体市场规模上来看,人工智能行业整体市场呈现稳步增长的趋势。中国人工智能市场规模(含软件、硬件及服务)达82亿美元,占全球市场规模的9 6%,在全球人工智能产业化地区中仅次于美国和欧盟,位居全球第三。
(报告出品方/作者:中信建投证券,阎贵成、于芳博)
一、人工智能行业简介及投资策略
1.1人工智能发展历史:一波三折,深度学习引领第三次发展浪潮
人工智能第一次发展浪潮:推理与搜索占据主导,但由于当时机器计算能力的不足而经历了第一次低迷期。人工智能(ArtificialIntelligence,缩写AI),是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。这一概念最早由麻省理工学院的约翰·麦卡锡在1956年的达特茅斯会议上提出,随之迎来了人工智能的第一次发展浪潮(1956-1974)。这一时期的核心在于让机器具备逻辑推理能力,通过推理与搜索尝试开发能够解决代数应用题、证明几何定理、使用英语的机器。该阶段的成果几乎无法解决实用问题,另外实际应用中人工智能计算量的增长是惊人的,特别是模拟人类感知带来的巨大运算量远超70年代的计算能力,因此人工智能经历了第一次低迷期。

人工智能第二次发展浪潮(1980-1987):专家系统开始商业化,场景局限性限制其发展。这一时期的核心是基于“专家系统”思想,让AI程序能解决特定领域问题,知识库系统和知识工程成为了这一时期的主要研究方向,专家系统能够根据该领域已有的知识或经验进行推理和判断,从而做出可以媲美人类专家的决策。典型代表如医学专家系统MYCIN,MYCIN具有450条规则,其推导患者病情的过程与专家的推导过程类似,开处方的准确率可以达到69%,该水平强于初级医师,但比专业医师(准确率80%)还是差一些。随着人们发现专家系统具有很强的场景局限性,同时面临着升级迭代的高难度和高昂的维护费用,因而AI技术发展经历了第二次低迷期。
从1993年开始,AI技术步入了第三次发展浪潮:深度学习引领浪潮。这一时期,计算性能上的障碍被逐步克服,2006年深度学习这一重要理论被提出,并解决了训练多层神经网络时的过拟合问题。2011年以来,深度学习算法的突破进一步加速了AI技术发展的第三次浪潮,标志性事件是2012年ImageNet图像识别大赛,其深度CNN网络的错误率仅为15%左右,远远好于第二名支持向量机算法的26%,这一结果迅速点燃了产业对神经网络和深度学习的兴趣,深度学习也快速的实现了商业化。
1.2人工智能产业链:关注AI芯片国产化,看好AI与金融、工业和医疗等方向结合
人工智能产业链:主要分为基础层、技术层和应用层。基础层主要包括人工智能芯片、传感器、云计算、数据采集及处理等产品和服务,智能传感器、大数据主要负责数据采集,AI芯片和云计算一起负责运算。技术层是连接产业链基础层与应用层的桥梁,包括各种深度学习框架、底层算法、通用算法和开发平台等。应用层则是将人工智能进行商业化应用,主要提供各种行业解决方案、硬件和软件产品。

基础层之AI芯片:CPU凭借通用性,依然在AI训练中占据重要位置;GPU凭借生态优势和强大的计算能力在AI应用中占据主导地位,FPGA/ASIC未来占比将不断提升。AI芯片是AI加速服务器中用于AI训练与推理的核心计算硬件,主要可以分为CPU/GPU/FPGA/ASIC/NPU等。CPU是目前常见的计算单元,具有很高的灵活性,但在大规模运算方面的性能和功耗表现一般。GPU因具有大规模的并行架构而能够在AI计算任务中实现较好的性能表现,但同时他会带来不菲的能耗成本。ASIC指的是人工智能专用芯片,在AI任务中有着最优秀的性能表现,其缺点是灵活性较低同时具有高昂的研发成本和能耗成本。与ASIC相反的是灵活性很高的可重复编程芯片FPGA,其高效的异步并行能力帮助其在AI计算加速中扮演重要的作用,但其成本较高。目前,GPU因其更强的计算能力和更为成熟的编程框架(如CUDA、OpenCL等),已经成为当前AI应用中的重要处理器和通用解决方案,而FPGA和ASIC则在特定的应用场景下有着各自的优势。AI芯片国产替代空间大。AI芯片是目前人工智能产业链中与国外差距较大的一个环节,CPU基本被Intel和AMD所垄断;GPU基本被英伟达、AMD所垄断;FPGA全球90%份额集中在AMD(Xilinx)、Intel(Altera)和Lattice等公司。
除AI芯片以外,基础层还包括光学、声学传感器,公司包括舜宇光学、禾赛科技等;计算平台主要指的是能够为人工智能计算提供所需的专用算力的数据计算中心,主要包括浪潮、阿里云、腾讯云、华为云等。数据服务主要指的是为各业务场景中的AI算法训练与调优而提供的数据库设计、数据采集、数据清洗、数据标注与数据质检服务,主要公司包括海天瑞声、爱数智慧、云测、标贝科技等;硬件设施主要指的是AI芯片和传感器。
技术层为包括核心算法在内的关键技术研发和生产企业,主要分为AI软件框架、理论算法、通用技术三个方面。软件框架简单来说就是库,编程时需导入软件框架,里面有各种模型或算法的一部分,主要提供给使用者设计自己的AI模型。目前市场上主要的深度学习开源框架有Google的TensorFlow、Facebook的Pytorch,而国内企业参与AI软件框架开发较晚,主要有百度的飞桨PaddlePaddle、腾讯Angel等。底层算法典型代表如GNN、CNN、RNN、Transformer等底层理论,相关参与方包括DeepMind、OpenAI、阿里达摩院等。通用技术主要指的是感知、认知、思维、决策等不同的应用方向的技术,包括计算机视觉、自然语言处理、知识图谱、推荐系统等,相关公司包括商汤科技(计算机视觉)、云从科技(计算机视觉)、科大讯飞(自然语言处理)等。随着底层理论算法的不断创新和通用技术的不断成熟,人工智能算法模型所需算力呈现指数级增长趋势。2012年以前,模型的算力需求以接近摩尔定律的速度增长(两年翻一倍)。2012年以后,模型训练所需计算量增长接近一年翻10倍。

应用层:安防占据AI应用主要场景,金融应用AI较好,医疗、工业具有一定快速应用前景。在应用场景维度,目前人工智能已在安防、金融、教育、交通、医疗、家居、营销等多垂直领域取得一定发展,尤其是AI+安防、金融、交通领域发展较快,典型公司有海康威视、商汤科技等;应用产品维度广阔,包括自动驾驶汽车、无人机、智能语音助手、智能机器人等,典型公司包括小马智行、科大讯飞等。从下游需求方来看,安防依然占据着AI主要需求,金融赛道则是下一个应用较好的场景,金融行业本身有较好的信息化基础以及数据积累,并且对精准营销、智能风控、反欺诈和反洗钱等机器学习产品有强烈需求,因此金融赛道应用AI较好。医疗、工业等赛道未来具有一定快速增长潜力,如AI在新药研发、手术机器人等领域的应用,工业领域也从机器视觉质检进一步拓展至更多领域。
从整体市场规模上来看,人工智能行业整体市场呈现稳步增长的趋势。2021年全球市场人工智能市场收入规模(含软件、硬件及服务)达850亿美元。IDC预测,2022年该市场规模将同比增长约20%至1017亿美元,并将于2025年突破2000亿美元大关,CAGR达24.5%。中国人工智能市场规模(含软件、硬件及服务)达82亿美元,占全球市场规模的9.6%,在全球人工智能产业化地区中仅次于美国和欧盟,位居全球第三。数据显示,中国人工智能市场规模由2016年的154亿元增长至2020年的1280亿元,年均复合增长率为69.9%。2022年中国人工智能市场规模将达2729亿元。
计算机视觉和自然语言处理是商业化落地较快的两项人工智能通用技术。计算机视觉相关技术已经十分成熟,技术落地效果超过人类水平,目前国内有35%的AI企业聚集计算机视觉领域,2020年市场规模近千亿,在所有领域中占比最高,是目前最具商业化价值的AI赛道。自然语言处理技术逐步实现从学术研究发展到商业应用推广的转变,核心产品及带动的相关产业规模均稳步增长,2021年自然语言处理核心产品规模预计达到219亿元,相关产业规模达到514亿元,未来几年年增长率均维持在20%左右。

1.3人工智能产业2023年投资策略
人工智能本质上是工具,要结合算法成熟度、数据积累和算力情况等多方面去判断其在不同领域的应用情况,同时下游行业发展的不同周期也一定程度上影响AI的应用,我们认为未来AI投资方向主要来自四个方面:
第一,算法相对比较成熟,数据训练也达到商业化要求,处于从1到N渗透的阶段,典型的如深度学习算法在金融、教育、工业等领域的应用,重点关注教育行业复苏以及工业领域的AI应用。深度学习在视觉、自然语言处理均属于发展多年且成熟度较高的算法,随着数据的不断积累和硬件边际成本的降低,在该领域不断渗透,尤其是以安防、金融、教育和工业等领域渗透较好。展望明年,我们认为,安防、教育等行业今年受疫情以及政府支出缩减等影响,明年有望复苏,同时受益于财政补贴等因素影响。工业和机器视觉的结合,是未来几年AI应用最重要的方向之一,核心成长逻辑有三方面:一是下游高成长带动需求,如新能源领域快速发展带动了相关智能视觉检测设备;二是国产替代,成本叠加服务优势,有望逐步替代基恩士、康耐视等;三是新冠疫情下,制造业对机器替代人的诉求更强了,该领域公司都具备品类拓张的能力。由于多数工业领域的机器视觉公司主要收入来自消费电子领域,今年受下游需求影响增速较慢,明年有望复苏。
第二,算法尚不成熟,数据积累量不够,算力也刚刚突破,整体看仍处于从0到1阶段,典型的如自动驾驶。我们认为智能驾驶是明年重要景气赛道之一:一是展望明年,消费需求有所复苏;二是智能驾驶的渗透率继续提升,明年下半年比亚迪、广汽Aion、吉利极氪等传统车厂明年都会有硬件达到L4级别的自动驾驶车型量产;三是人民币进入升值通道,板块毛利率将逐步修复。因此,明年整个板块在总量、渗透率还有盈利水平上都将有向好的边际变化。
第三,新算法的应用,实现从0到1,创造出新的需求。如DiffusionModel(扩散模型)的推出,基于扩散模型的文本生成图像模型越来越多,并很快扩展到文本生成视频、文本生成3D、文本生成音频等,创造出新的业态和应用。
第四,AI软硬件平台的国产化比例提升。在中美贸易战、科技战持续深化的背景下,加强对卡脖子的关键核心技术研发的支持,加速国产替代的步伐,重点看好FPGA、EDA等细分板块。
二、人工智能算法
2.1深度学习引领风潮
深度学习是多层人工神经网络和训练它的方法。人工智能是个大范畴,机器学习是人工智能的一个研究分支——通过计算模型和算法从数据中学习规律,机器学习有很多种算法,包括神经网络、kNN、朴素贝叶斯、支持向量机(SVM)等算法。其中,神经网络经过不断的迭代,从一层迭代到多层,因此可以实现更准确的判断,标准性事件是ImageNet图像识别比赛中,深度神经网络战胜支持向量机算法,并在此后逐步超越人类。其中,深度学习的理论基础就是神经网络,神经网络层数够深就可以称为深度模型。
深度学习是过去十年AI研究最热方向,也是商业化应用最广泛的算法之一。根据人工智能发展报告(2020)数据显示,过去十年中,有5405篇以卷积神经网络为研究主题的论文在人工智能国际顶会顶刊论文中发表,其总引用量达299729,并且在这些顶会顶刊论文引用量排名前十的论文中出现过125次,是2011-2020年最热门的AI研究主题。深度学习通过学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字,图像和声音等数据的解释有很大的帮助。深度学习在包括计算机视觉、自然语言处理、推荐系统等相关领域都取得了优异成果。

神经网络的研究是深度学习发展的基础,上个世纪50-60年代神经网络只能处理线性分类,因此应用领域狭窄,使得神经网络研究陷入20年停滞。在深度学习概念被明确提出之前,针对神经网络的研究为后续深度学习的提出和发展完成了基础性工作。第一代神经网络从1958年感知机算法被提出开始,其可以对输入的多维数据进行二分类,并通过梯度下降(使网络的预测值与网络的实际/期望值之间的差异不断缩小)的方法从训练样本中自动学习更新权值(模型进行分类的参数),由此引发了第一次神经网络研究的热潮。1969年,Minsky在著作中证明了感知机本质上只是线性模型,对于即使是最简单的非线性问题都无法正确分类,随后导致了对神经网络的研究陷入了近20年的停滞。
上个世纪80-90年代神经网络具备持续优化和解决非线性能力后,开启第二代神经网络研究热潮,但由于存在梯度消失问题,研究也逐渐冷淡。Hinton于1986年提出了反向传播算法(从最后输出的神经元开始,反向更新迭代每一个神经元的权值,计算当前数据通过神经网络后的结果与实际结果的差距,从而根据差距进行参数优化),并采用Sigmoid作为激活函数进行了非线性映射,让神经网络具有了解决非线性问题的能力,由此开启了第二代神经网络研究热潮。但后续由于神经网络缺乏相应的严格数学理论支持,甚至被指出存在梯度消失问题(随神经网络层数增多,靠近输入层的层之间的权重无法得到有效修正),严重影响深度神经网络的训练效率和效果,因而神经网络的第二次热潮也逐渐冷淡。这一时期中,也出现了具有革新意义的模型,如CNN-LeNet和LSTM模型,其分别在手写数字识别、序列建模两个方面取得了良好效果,但由于神经网络研究整体处于下坡而并没有引起足够关注。解决了梯度消失以及利用GPU进行深度学习训练后,深度学习图像识别准确率大幅提升,掀起深度学习第三次研究热潮,并持续至今。2006年Hiton提出了梯度消失的解决方案以及利用GPU进行深度学习训练,首次提出了深度学习这一概念。2011年,新的ReLU激活函数被提出,有效抑制了梯度消失的问题。2011年,微软首次将深度学习应用在语音识别上,取得了重大突破。2012年,Hiton课题组参加ImageNet图像识别比赛,其深度学习模型AlexNet夺得冠军,识别率远远超越了基于SVM方法的第二名。理论上的不断完善和硬件算力(GPU)的突破共同在全世界范围内掀起了研究深度学习的热潮并持续至今。
2012年开始,在计算机视觉领域内,深度学习不断迭代出性能更好的架构。如2014年的VGG、GoogleNet。与之前的模型相比,VGG通过增加网络深度的方法,在一定程度上提升了神经网络的效果。其中VGG-16包含了16层,参数量达到了1.38亿。而GoogleNet(Inception)则采用宽度代替深度,并引入了模块化思想,其核心思想是分别用不同大小的卷积模块对前层的输入进行运算,再对各个模块运算的结果进行通道组合。最终GoogleNet(Inception)以远小于VGG的参数量实现了相当的性能效果。

2015年的ResNet通过残差结构进一步优化了神经网络的性能,而后MobileNet的提出让神经网络嵌入到移动端成为可能,NAS和RegNet等算法及模型的应用,使得神经网络可以由机器自动设计。ResNet的核心思想在于在输出跟输入之间引入一个短路连接(残差模块),让每一层的输入在网络深度增加的时候也能得以保留,进而解决了由于网络深度过大带来的梯度消失问题,让训练出成百上千层的神经网络成为可能。2017年,谷歌团队提出MobileNet这一轻量级网络结构,相比于传统的卷积操作能够大大的减少参数量和提高网络运行的特性,进而让其能够有效嵌入到移动端使用的网络模型中。2019年开始,神经网络架构搜索(NeuralArchitectureSearch,简称NAS)开始兴起,核心思路是从手工设计神经网络到机器自动设计神经网络。此后,RegNet进一步优化这种机器自动设计神经网络的过程,RegNet也是搜索最优的网络结构,但是又与NAS有明显区别,NAS在定义的搜索空间内找到一个最优网络,RegNet则是在一个巨大的初始搜索空间中,不断缩减,最终获得一个高性能模型更加集中的子空间,在这个过程中,发掘网络优化准则,增强网络优化的可解释性。
自然语言处理领域中的Transformer结构的提出是深度学习发展过程中的重要里程碑,为后续深度学习的进一步发展奠定基础。2017年,为NLP下游任务中的机器翻译而提出的Transformer模型成为了新的重要创新。其利用多个注意力模块的组合,让神经网络得以利用有限的资源从大量信息中快速筛选出高价值信息,不断提取并学习目标对象中更为重要的特征,进而实现性能的提升。后续OpenAI和Google基于Transformer分别提出了GPT和BERT,提升了诸多自然语言处理下游项目的最优性能。后续Transformer强大的特征提取能力被包括计算机视觉在内的其他人工智能领域广泛采用,其核心注意力模块逐渐成为深度学习中不可或缺的部分,大幅推进了各领域人工智能算法的性能表现。后续人工智能深度学习中的大部分模型框架也都是建立在Transformer的基础上,包括引发热议的GPT-3和ChatGPT(2.3节)。至此,深度学习便从最初简单的感知机算法,简单的神经网络,发展到目前参数量达到数千万亿的庞大而复杂的神经网络,成为当下人工智能技术、应用、产业中的主流解决方案。
深度学习这一技术所展现出来的变革世界的潜力超越了过去的科技创新,预计将以前所未有的方式改变世界的生产生活方式,创造大量的经济价值。根据ARK数据显示,过去二十年来,互联网为全球股票市值增加了13万亿美元。而截至2020年,深度学习已经创造了2万亿美元的市值。根据ARK测算,深度学习将在未来15-20年内,为全球股票市场增加30万亿美元的市值。

2.2计算机视觉:AI下游最好的应用方向
计算机视觉是“赋予机器自然视觉能力”的学科。实际上,计算机视觉是研究视觉感知问题的学科:视觉感知是指对“环境表达和理解中,对视觉信息的组织、识别和解释的过程”。核心问题是研究如何对输入的图像信息进行组织,对物体和场景进行识别,进而对图像内容给予解释。更进一步的说,就是指用摄影机和计算机代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图像处理,用计算机处理成为更适合人眼观察或传送给仪器检测的图像。从计算机视觉的整理发展历程上来看,在研究对象的丰富、研究方法的革新、研究数据的完善等过程中不断发展。50年代,主题是二维图像的分析和识别。60年代,开创了三维视觉理解为目的的研究。70年代,出现课程和明确理论体系。1989年,YannLeCun将一种后向传播风格学习算法应用于卷积神经网络结构。在完成该项目几年后,LeCun发布了LeNet-5——这是第一个引入我们今天仍在使用的一些基本成分的现代网络。90年代,特征对象识别开始成为重点。21世纪初,出现真正拥有标注的高质量数据集。随后便是Hinton提出深度学习,其学生于2012年赢得ImageNet大赛,让CNN真正家喻户晓,也让深度学习方法计算机视觉研究领域流行,在应用端实现了百花齐放。
计算机视觉领域中早期的重要算法同时也是深度学习发展中的重要革新(2.1节),后续计算机视觉在内容生成、特征提取两个方面又向前迈出了一大步。2018年末,英伟达发布的视频到视频生成(Video-to-Videosynthesis),其通过精心设计的发生器、鉴别器网络以及时空对抗物镜,合成高分辨率、照片级真实、时间一致的视频,实现了让AI更具物理意识,更强大,并能够推广到新的和看不见的更多场景。2019年,更强大的GAN,BigGAN被提出,其拥有更强的学习技巧,由它训练生成的图像连它自己都分辨不出真假,被誉为史上最强的图像生成器。2020年,随着VIT的提出,Transformer开始在计算机视觉领域进行应用,颠覆了传统的CNN结构,后续Swim-Transformer被提出,通过分而治之的思想解决了Transformer应用到图像领域时面临的:视觉实体变化大影响不同场景下性能和图像的高分辨率带来的高计算量问题,在计算机视觉的多个下游任务中实现了对CNN结构的压倒性优势。
随着计算机视觉算法和技术的不断成熟,下游应用场景也逐步渗透和拓展。从2018-2021获得投资的计算机视觉企业来看,其业务领域遍布公安、交通、金融、工业、医疗等各行各业。从核心产品和产业规模来看,计算机视觉产品技术在泛安防中的应用深受政策及财政支持,多年以来一直是计算机视觉乃至整个国内人工智能产业实际落地的重要基石。2021年,国内泛安防领域计算机视觉核心产品市场规模已达到531亿元,占计算机视觉总核心产品规模的70.7%,这一领域的代表公司有商汤科技、海康威视、大华股份;金融领域主要通过计算机视觉产品技术完成人脸识别、证照识别及行为动作检测等工作,代表公司有云从科技(人脸识别),格灵深瞳(行为动作识别);医疗领域中,主要借助计算机视觉技术进行AI医学影像辅助诊断及新型智能医疗器械开发,代表公司为依图科技;互联网领域中,计算机视觉算法技术主要基于AI技术开放平台,通过API调用模式开放给更广泛的开发者,代表平台有阿里云(阿里巴巴)、腾讯云(腾讯)、华为云(华为)。工业领域中,视觉算法被应用在生产过程中的工况监视、成品检验、质量控制等方面,主力打造生产制造智能化,主要代表公司为凌云光(零件生产监测)、奥普特等。随着计算机视觉相关技术及硬件设施的加速发展与成熟,以及各行业数字化程度的不断提升,计算机视觉有望在更多具体场景中创造更大的经济价值。

从竞争格局上分析,目前中国计算机视觉行业主要分为三大阵营:1)AI算法公司,多以细分赛道为具体发力点,提供定制化的解决方案,代表企业为“CV四小龙”商汤科技、旷视科技、云从科技、依图科技及格灵深瞳等;2)互联网巨头,借助更完整的产业生态逐步在各个领域进行渗透,代表企业包括阿里巴巴、百度、腾讯、华为等;3)传统安防巨头,在云边融合的架构下,借助原有的硬件优势和市场优势,逐步引入算法,研发智能化解决方案,代表公司包括海康威视,大华股份等。目前我国计算机视觉市场呈现出市场集中度高的特点,以“CV四小龙”为代表的头部企业已逐渐占据国内CV的主要市场份额,2020年,商汤科技市场份额排名第一,达到17.4%;其次为旷视科技,市占率为15.2%;云从科技及依图科技分别占比9.8%、9%。目前CV四小龙等公司凭借算法享有一定的先发优势,但随着计算机视觉技术进一步走向具体场景的商业化应用,在场景应用层面享有更多资源的互联网巨头和拥有硬件优势的传统安防巨头也将获得更大发展机会,未来的核心比拼仍将是应用端的商业化落地。
2.3AIGC成为人工智能新方向,扩散模型引发研究热潮
AIGC即AI-GeneratedContent,是一种新的内容生产方式。AI从理解内容,走向了可以生成内容,甚至能够创造出独立价值和独立视角的内容。事实上,使用计算机生成内容的想法自上个世纪五十年代就已经出现,早期的尝试侧重通过让计算机生成照片和音乐来模仿人类的创造力,但是与当今合成媒体不同的是,早期阶段生成的内容很容易与人类创建的内容区分开来。人工智能经历数十年的重大飞跃,目前使用计算机生成的内容已经达到高水平的真实感。根据中国信通院划分,AIGC经历了早期萌芽阶段(1950s-1990s),沉淀积累阶段(1990s-2010s)以及快速发展阶段(2010s-至今)。其中,早期萌芽期受限于科技水平,AIGC仅限于小范围实验,并没有取得重大突破,例如通过将计算机程序中的控制变量换成音符完成了历史上第一支由计算机创作的音乐作品——弦乐四重奏《依利亚克组曲(IlliacSuite)》,或者世界第一款可人机对话的机器人“伊莉莎”等。沉淀积累阶段受益于深度学习的重大突破,自然语言处理、语音识别等领域开始向实用性转变,例如此阶段诞生了全世界第一部完全由人工智能创作的小说;微软推出全自动同声传译系统。快速发展时期,AIGC迎来百发齐放阶段,该阶段人工智能算法可以生成极高质量的图片、视频、绘画作品等。
AIGC当前快速发展得益于生成模型的飞跃。与用于监督任务的判别模型不同的是,生成模型通过学习某个样本生成的概率对新数据进行建模,即判别模型可以识别图像中的人,而生成模型可以生成一个以前从未存在过的人的新图像。生成模型的飞跃是GAN(生成对抗网络)的出现,自GAN推出后,AI生成的媒体模型已经实现了逼真的合成,包括照片级图像的生成、声音克隆以及面部识别等。AI内容创作也已经完成了从文字到图画再到视频的跃迁。
GAN网络包括两部分,一个生成器和一个判别器。生成器负责生成类似输入数据的新内容,判别器是将生成的输出与真实数据区分开来,这两个部分在一个GAN网络反馈循环中相互竞争并试图超越对方,导致生成输出的真实性逐渐增加。在GAN网络基础上有两个经典的延伸,一个是StyleGAN,能够通过将图像不同部位进行区分,从而能够直观控制生成图像的细节;另外一个是in-domainGAN,支持对GAN生成图像进行编辑,从而可以在现有图像进出上进行增添元素。除了用于图像处理上,GAN网络也被用于视频配音、图像动画等应用中。AIGC中,文本生成领域也得益于GPT-3等语言模型的出现而大放异彩,GPT-3在用于文本处理之外,也可以用于文本到图像的生成。

AIGC已被广泛用于多种行业,包括娱乐、客户服务与营销。例如在移动程序Reface中,用户能够在视频剪辑和GIF中换脸以与朋友分享;在Pinscreen上创建AI虚拟助手,在直播中进行面部替换;甚至于可以在视频中生成嘴唇运动模型,从而允许将视频翻译成另外一种语言,嘴唇运动和配音之间没有任何明显差异。根据Capterra调研显示,虽然只有33%的营销人员使用AIGC,但大多数都对AIGC内容质量都感到满意。
AIGC领域投资力度空前。AIGC文字生成领域,负责文字生成的AIGC公司彩云小梦、聆心智能获得了天使轮融资,Jasper.ai更是在A轮融资阶段获得了1.25亿美元的融资,估值15亿美元。AIGC图像生成领域,负责AI作画的初创公司诗云科技先后获得了天使轮、Pre-A轮融资,ZMO.AI获得了800万美元的A轮融资,英国开源人工智能公司StabilityAI获得了1.01亿美元的融资,目前该公司估值高达10亿美元,成为了行业独角兽。AIGC视频生成领域,负责产出视频的小冰公司A轮融资由高瓴资本领投,目前估值超过10亿美元,Meta的新产品Make-A-Video也可以直接通过文字生成视频,谷歌也推出了生成视频的AI模型ImagenVideo、Phenaki。
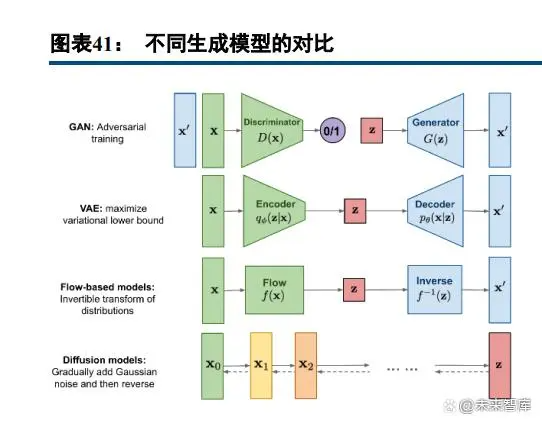
扩散模型(DiffusionModel)正引起AIGC领域新一波浪潮。生成模型主要包括GAN(生成对抗网络)、VAE(变分自编码器)、基于流的模型以及扩散模型等。GAN模型具有对抗性训练性质,具有潜在的不稳定训练和较少的生成多样性;VAE依赖于替代损失;基于流的模型必须使用专门的体系结构来构建可逆变换。扩散模型的灵感来自非平衡热力学,模型定义了一个扩散步骤的马尔可夫链,在正向扩散过程中,将随机噪声添加到数据中,然后学习反向扩散过程,从噪声中构建所需的数据样本。与VAE或基于流的模型不同,扩散模型是通过固定过程学习的,并且潜在变量具有高维性。在webofscience平台上,通过关键字“diffusionmodel”在webofscience核心合集数据库中按照主题检索(检索时间为2022年11月30日),2020年相关主题论文为446篇,2021年相关论文456篇,为近二十年高峰。
扩散模型成为ICLR热门关键词之一。根据人工智能顶级会议ICLR2023发布的评审结果,扩散模型成了今年ICLR的热门关键词之一,以扩散模型为研究主题的投稿论文数量出现暴涨。扩散模型引发了席卷式的AIGC热潮,今年4月OpenAI发布文本生成图像模型DALL·E2,之后谷歌推出Imagen,直接对标DALL·E2,文本生成图像领域开始出现激烈竞争。今年8月,初创公司Stability.AI发布深度学习文生图模型StableDiffusion,开源后更是一石激起千层浪,后续基于扩散模型的文本生成图像模型层出不穷,并很快扩展到文本生成视频、文本生成3D、文本生成音频等。
扩散模型主要包括三个子类别,已应用于各种生成建模任务。第一类扩散模型为DDPM(去噪扩散概率模型),DDPM是一种潜在变量模型,利用潜在变量来估计概率分布,可以看做是一种特殊的VAE;第二类扩散模型是NCSN(噪声条件评分网络),通过评分匹配训练共享神经网络来估计不同噪声水平下受扰数据分布的评分函数;第三类扩散模型是SDE(随机微分方程),代表模拟扩散的方式。当前扩散模型已用于各种生成建模任务,如图像生成、图像超分辨率、图像填充、图像编辑等领域。未来,扩散模型将在图像去雾化、视频异常检测、物体检测、视频模拟等领域有所突破。
2.4NLP发展情况
自然语言处理(naturallanguageprocessing,NLP)是基于自然语言理解和自然语言生成的信息处理技术,近些年来,自然语言处理在机器翻译、智能语言助手、文本自动分类都取得了突破性进展。1950年,图灵发表论文“计算机器与智能”,其中提到著名的用于衡量机器智能程度的图灵测试,可以被认为是自然语言的开端,自然语言处理的技术发展大致可以分为三个阶段:规则—统计—深度学习。20世纪50年代到90年代,研究人员重点关注语言的规则,从语言学的角度来解析自然语言的规则结构,从而实现自然语言的处理,但是这个阶段还不能处理复杂的语言问题,因而没有太大的应用价值。20世纪90年代以后,随着互联网的高速发展,语料库的日益丰富、计算机运行速度的提升以及统计方法的成熟,极大地推动了自然语言处理技术的发展。
2006年深度学习算法提出,随后很快被应用到自然语言处理领域,取得了惊人的成绩和广泛的应用。诞生了多种神经网络语言模型,包括多层感知机(MLP)、卷积神经网络(CNN)、循环神经网络(RNN)和长短记忆(LSTM)网络,但是都存在一定的不足,MLP难以捕捉局部特征,CNN难以获得远距离特征,RNN难以充分利用并行计算加速,LSTM减少了网络的层数,相对来说更容易优化。2017年,采用注意力机制的Transformer模型被引入到自然语言处理以后取得了极大的成功。注意力机制更加关注上下文的相关程度和深层的语义信息,因而Transformer模型在长距离建模和训练速度方面都优于传统的神经网络模型。近年来,在Transformer模型的基础之上,衍生出了GPT、BERT等超大规模的动态预训练语言模型,除此以外,还有基于Word2vec的词向量方法提出的ELMo模型也得到了大规模的应用,ELMo考虑了上下文的词向量表示,较好的解决了多义词的问题。
GPT模型是OpenAI公司于2018年6月提出的动态预训练模型,版本也在不停更新迭代,最新版本GPT-3是目前最为强大的预训练模型之一,于2020年5月提出。GPT每代模型的参数数目不断提升,初始GPT版本只有1.17亿个参数,GPT-2参数超过10亿,GPT-3参数高达1750亿,使用了高达45TB的训练样本。GPT-3已经商业化落地,基于GPT-3产生的APP达300多个,覆盖传媒、营销等领域,OpenAI以API的形式向开发者提供有偿的GPT-3模型使用权限,按照token(1000tokens=750words)使用量收费,1000tokens收费在0.0004~0.2美元之间。BERT模型由Goegle于2018年10月提出,BERT使用包含1.1亿个参数的BERTBASE和包含3.4亿个参数的BERTLARGE,在自然语言识别的SQuAD测试中,BERT模型的表现甚至超越了人类。基于BERT模型衍生出了更多具备特定优势的模型,例如增强长文本理解能力的XLNet,具备强大文本生成能力的BART等。
随着预训练语言模型的提出和计算机算力的快速提升,自然语言处理技术已经进入全新的发展阶段。预训练模型通过无需人工标注的大规模文本库进行高算力的预先训练,得到通用的语言模型和表现形式,再经过特定应用环境对预训练模型进行微调,从而在各种下游应用领域得到目标任务的快速收敛和准确率提升。各种预训练语言模型还在快速的更新迭代,不断刷新自然语言处理任务的表现记录,预训练模型已经在自然语言处理中得到了广泛应用。当前自然语言处理技术在某些领域已经可以媲美人类水平,同时具备多种功能应用,包括文本检索、信息过滤、机器翻译、客服问答、文本生成等,在金融、教育、医疗、互联网行业当中得到了广泛的应用,随着自然语言处理和传统行业的深度融合,将人力从部分重复性的语言工作当中解放了出来,实现了人工智能替代。
2022年11月30日,OpenAI发布了ChatGPT人机对话交互模型,相比过去的人机对话模型,ChatGPT展现出更贴近人类的思维逻辑,可以回复用户的连续问题,具有一定的道德准则,减少了错误问答的出现概率,具备代码的编写和debug功能。ChatGPT在人机对话上到达了前所未有的高度,模型开放测试一周用户便突破了百万级别。ChatGPT作为GPT3.5的微调版本,采用了人类反馈强化学习方式(RLHF)和近端优化策略(PPO),通过奖励模型的设定,极大减少了无效的、编造的、有害的答案出现概率,更多输出了人们期望的答案。当前ChatGPT已经在诸多问答环节里表现出极高的拟人化,足以以假乱真。目前ChatGPT处于免费的开源公测阶段,仍在优化迭代过程中。我们预计,超大规模的自然语言预处理模型将率先在传媒营销、搜索引擎增强、代码编程等领域实现商业落地。当前自然语言处理的快速发展已让我们更加临近图灵测试的奇点,未来人工智能将深刻地改变我们的生产生活方式。我们应当重点关注自然语言处理的技术进展、大规模商业的落地途径以及我国超大规模预训练模型的发展进展。
三、AI基础层及应用层投资机会:自动驾驶、机器视觉景气度高,FPGA芯片国产替代空间大
3.1自动驾驶:技术不断突破,渗透率不断提升
3.1.1自动驾驶技术不断突破,Transformer模型应用进一步提升准确率
视觉Transformer正推动自动驾驶向前迈进。自动驾驶初期阶段,主要目标是让汽车在单车道内行驶,随着驾驶复杂性,需要对路况进行影像提取与3D建模等。特斯拉自动驾驶算法使用的是多任务学习HydraNets架构,从而让汽车共享相同神经网络或特征提取器的同时能进行交通灯检测、车辆避让等多项任务。特斯拉自动驾驶算法中,首先让车载摄像头使用RegNet(残差网络)对路况/汽车进行原始图像提取。在每个摄像头都处理完单个图像后,使用具有多头自注意力的Transformer模型进行处理,Transformer模型不仅解决了CNN算法在BEV(鸟瞰图)遮挡区域预测问题,同时还有更高的性能和算法准确度。后续将处理结果进行多尺度特征、视频神经网络等处理,从而完成整个自动驾驶算法。近年来Transformer凭借传统CNN算法所不能企及的感知能力以及其优秀的鲁棒性和泛化性,已逐步取代IPM、Lift-splat、MLP成为BEV(鸟瞰图)感知领域的主流算法。

特斯拉中的Transformer模型侧重于使用交叉注意力。根据特斯拉2021人工智能日,特斯拉Transformer算法主要原理为:首先初始化一个输出空间大小的栅格,在输出空间中利用正弦和余弦的位置编码进行填充,用多层感知机将其编码成一组查询向量。所有的图像及其特征均生成属于自己的键和值。最后将键和值查询输入到注意力中。我们认为Transformer模型因其注意力机制解决了CNN中卷积层遮挡区域检测问题,成为了自动驾驶领域的首选,交叉注意力机制目前也更有利于Transformer模型在汽车上进行部署,Transformer模型正推动自动驾驶技术实现飞跃式的迭代。2022年6月2日,马斯克发布推特称,Transformer正在取代C启发式算法去处理视觉神经网络中大量的节点,特斯拉全自动驾驶正在使用运行在TRIP芯片上的GPT算法实现计算机视觉。根据特斯拉2022AI开放日,特斯拉全自动驾驶(FullSelfDriving(beta))客户已从2021年的2000个增长到2022年的16000个。
2022年11月24日,马斯克发布推特称,特斯拉全自动驾驶(FullSelfDriving(beta))已经可以提供给北美任何一个购买相关服务的车主使用,成为特斯拉Autopilot/AI团队一个重要里程碑。在特斯拉的引领下,自动驾驶功能渗透率将不断提升,其中智能驾驶域控制器率先放量。
3.1.2智能驾驶渗透率继续提升,L3车型开始落地
深圳发布《深圳经济特区智能网联汽车管理条例》,自动驾驶政策放开临近。近些年来,为了支持自动驾驶等智能汽车行业的发展,我国政府陆续发布了许多政策。例如,2018年工信部发布《车联网(智能网联汽车)产业发展行动计划》,指出要加快建设智能网联汽车制造业创新中心,促进产业链上下游及与相关行业之间的融合。2022年11月,工信部发布《关于开展智能网联汽车准入和上路通行试点工作的通知(征求意见稿)》,将在全国智能网联汽车道路测试与示范应用工作基础上,选出符合条件的企业和智能网联汽车产品,开展准入试点,其中智能网联汽车搭载的自动驾驶功能为L3和L4级。2022年6月,深圳市发布《深圳经济特区智能网联汽车管理条例》,这是国内首部关于智能网联汽车管理的法规,对智能网联汽车的准入登记、上路行驶等事项做出具体规定。北京、上海、重庆、四川等多地也均发布相关支持政策。
L2级别自动驾驶前装渗透率不断提升。根据上险量数据,2022年10月我国智能汽车销量39.73万辆,同比增长68.1%,渗透率为24.78%。在2022年世界智能网联汽车大会上,工信部副部长辛国斌介绍,今年上半年具备组合驾驶辅助功能的乘用车销量达288万辆,渗透率升至32.4%,同比增长46.2%。国内自动驾驶正进入发展快车道。根据高工智能研究院数据,截至2022年9月,我国前向L2级ADAS前装渗透率已达27.7%,2019-2021年该数据分别为2%、12%、19.4%。未来国内自动驾驶级别将从L2向L3/L4转换,例如上海市发布《上海市加快智能网联汽车创新发展实施方案》指出,到2025年,上海市初步建成国内领先的智能网联汽车创新发展体系,产业规模力争达到5000亿元,具备组合驾驶辅助功能(L2级)和有条件自动驾驶功能(L3级)汽车占新车生产比例超过70%,具备高度自动驾驶功能(L4级及以上)汽车在限定区域和特定场景实现商业化应用。

2023年新出自动驾驶车型中L2依旧为主流,L3/L4开始落地。2023年多家车厂推出L3级别自动驾驶汽车,从半自动驾驶阶段跨越至特定场景中完全自动驾驶阶段。例如现代汽车将在2023年推出包括捷尼赛思G90和起亚EV9在内的多款L3级别自动驾驶汽车;宝马L3自动驾驶系统“PersonalPilot”将在2023年底推出,并将在宝马7系列上使用;小米纯电汽车搭载L3级别自动驾驶系统,目前正处于测试阶段,预计2024年上半年量产;奇瑞与华为将合作在2023年推出搭载L3级别自动驾驶系统的E03与E0Y。部分自动驾驶汽车车厂直接跳过L3,直接从L2迈向L4级别。例如通用公司旗下的Cruise支持L4级别驾驶,推出Origin车型;百度发布ApolloRT6,支持L4级别自动驾驶,并将于2023年开始试运营。
3.2FPGA:高成长、高壁垒的优质赛道,看好FPGA芯片国产替代
3.2.1FPGA:时延低、单位能耗比低、并行运算更高效的可编程芯片,中国市场快速增长
FPGA的全称为Field-ProgrammableGateArray,即现场可编程门阵列。主要由可编程的逻辑单元(LC)、输入输出单元(IO)和开关连线阵列(SB)三个部分构成。可编程逻辑单元通过数据查找表LUT中存放的二进制数据来实现不同的电路功能,开关阵列通过内部MOS管的开关控制信号连线的走向。
FPGA的无指令特征,使其具有时延低、单位能耗比低、并行运算更高效三大特征。1.时延低:因无指令的特征,所有程序都自存储器读取结果,不需要像CPU一样进行程序编译等过程,因此算法运行时间远小于CPU和GPU,适用于时延要求高的领域。2.单位能耗比低:无指令特征下,节省了编码、译码等过程,因此能耗比更低。3.并行运算更高效:因无指令特征,FPGA可以做到异步的并行,如果说GPU的计算是1名指挥员协调10条生产线,ASIC/FPGA就是由10名指挥员分别指挥自己的生产线。因此在执行并行运算的时候(AI领域),与CPU、GPU相比,FPGA具有更高的速度和极低的计算能耗,使深度学习实时计算更容易在端侧执行。
FPGA的最大特点是可编程特性。逻辑单元、开关阵列可编程,使得FPGA功能可以随时改变,从而具有可编程特性。FPGA基于的是查找表技术,任何逻辑都储存在SRAM电路中,而SRAM电路是易失性存储器,断电后数据则不被保存,因此FPGA通过改写SRAM中的数据表以及开关阵列,即可实现不同功能。
全球市场快速增长:根据Frost&Sullivan数据,2019年全球FPGA芯片产业规模约为56.8亿美元,2016-2019年复合增速为9.38%。随着全球新一代通信设备部署以及人工智能与自动驾驶技术等新兴市场领域需求的不断增长,FPGA市场规模预计将持续提高。中国市场增速快于全球市场:根据Frost&Sullivan数据,中国FPGA市场从2016年的约65.5亿元增长至2019年的129.6亿元,复合增速为25.48%。

工业、汽车电子、数据中心成为FPGA增长最快的细分市场。FPGA芯片因其现场可编程的灵活性和不断提升的电路性能,拥有丰富的下游应用领域,包括网络通信、工业控制、消费电子、数据中心、汽车电子等。2020年中国FPGA市场下游应用中,通信领域和工业控制占比最高,分别达到41%和32%。随着智能汽车、AI推理的不断渗透,汽车电子、数据中心、工业成为FPGA增长最快的细分市场,预计2022-2025年汽车FPGA市场复合增长率将达到13.3%,数据中心FPGA市场复合增长率将达到12.7%,除此之外,工业视觉也有较快的增长。
海外龙头AMD和Intel的FPGA产品价格上涨,凸显行业景气度。根据国际电子商情的消息,由于疫情冲击、供需情况紧张和产品成本上涨,AMD将从2023年1月9日起对旗下Xilinx品牌的FPGA产品进行涨价,其中Spartan6系列涨价25%,Versal系列不涨价,其他Xilinx产品全部涨价8%。此外Xilinx产品的产能也受到影响,产品的交货周期存在不同程度的延长,16nmUltraScale+系列、20nmUltraScale系列、28nm7系列都需要20周,预计到2023年第二季度末才能缓解交付压力。剩余Xilinx成熟节点产品的标准交货周期持续到2023年第一季度末。2022年7月底,Intel也通知其FPGA产品从2022年10月9日起全线涨价,其中ArriaV、Arria10、CycloneIV、CycloneV、Cyclone10、MAXV、MAX10、eASIC等新款涨价10%,ArriaII、CycloneII、CycloneIII、MAXII、StratixIII、StratixIV、StratixV、EPCQ-A等旧型号产品涨价20%。两家海外龙头的涨价主要集中在旧产品和中低端市场,属于国产替代的可覆盖范围。海外FPGA产品的涨价将提高国内公司的使用成本,从而推动国产替代的节奏。
全球FPGA公司均呈现快速增长,:1)AMD:全球第一大FPGA公司Xilinx于2020年以350亿美元的价格被AMD收购,该交易于2022年2月14日完成。去掉原本属于AMD嵌入式芯片业务合并报表因素影响,2022Q2和Q3的AMD的FPGA业务营收达到12.01亿美元和12.62亿美元,与对应的Xilinx财年数据比较,同比增长36.63%和34.83%;2)IntelFPGA业务预计今年增速达26%,持续推出新产品,行业成长空间广阔。2022英特尔FPGA中国技术周上,公司预计今年FPGA业务收入超24亿美金,同比去年19亿美金增长26%,是过去五年来增速最快的一年;3)Lattice营收近五年持续增长,2021年后增速加快,主要增长点为工业和汽车、通信与计算两大板块。2021年收入5.15亿美元,同比增长26.3%,2022年前三季度收入4.8亿美元,同比增长29.8%,增速进一步加快。工业和汽车主要用于工业自动化和机器人、ADAS和信息娱乐应用,在2021年收入2.26亿美金,同比增长34.4%。2022Q1-Q3收入2.3亿美元,同比增长38.6%,是增速和占比最大的一块。通信和计算主要用于数据中心服务器、客户端计算和5G基础设施,在2021年收入2.18亿美元,同比增长24.8%。2022Q1-Q3收入2.05亿美元,同比增长29.7%。消费和许可与服务业务开始增长,在2021年分别同比增长11.3%和4.4%。FPGA:高成长、高壁垒的优质赛道:随着架构、先进制程的迭代,FPGA从传统通信密集领域的应用拓展到了计算密集领域,包括AI、边缘计算、自动驾驶等新领域的应用,整个行业打开了新的成长空间。
3.2.2FPGA呈现寡头垄断市场格局,国产替代空间大
全球FPGA市场呈现寡头垄断格局:从全球FPGA市场竞争格局来看,相关市场目前基本由龙头企业把控,Xilinx和Intel占比达到80%,目前中国厂商在全球市场中所占份额较低。中国FPGA市场由赛灵思(Xilinx)和英特尔(Intel)两家供应商主导,两家公司在中国的市场份额超过70%。目前本土供应商也占据了一定市场份额,2021年在中国的总份额超过15%,随着国产化的推进,国内市场具有广阔的提升空间。

美国限制国内AI芯片发展,FPGA最大下游通信领域频受制裁:2022年10月7日,拜登政府宣布了一项关于人工智能(AI)和半导体技术对中国的新出口管制政策。此外,部分公司也受到制裁。以华为为例,美国政府禁止华为购买美国元器件和软件。通信是FPGA最大的下游市场,在中国市场中占比超过40%,华为是全球第一大通信设备商,2021年占全球通信设备市场28.7%的份额,是通信FPGA主要需求方,以华为为主的这些受到制裁的大客户无法或受限制使用国外FPGA。信创快速推进,FPGA将受益于信创发展:自2021年以来,继党政信创展开后,包括三大运营商及金融机构持续展开国产化服务器集采,表明信创产业正在不断向行业延伸。信创产业庞大,其中芯片、整机、操作系统、数据库、中间件是重要的产业链环节。2022年下半年开始信创将继续快速推进,整体大趋势已经形成。FPGA作为重要的计算芯片,服务器中将其应用于后端的通信板卡。同时,FPGA是电力、交通领域重要的通信部件,在银行系统中应用于企业级交换机路由器,在云计算中也起到运算加速作用。
3.3AI+工业:助力制造业转型升级,看好国产替代机会
我们认为,在人工智能和工业制造的结合过程中,应当重点关注工业机器视觉、工业互联网和EDA。
3.3.1工业机器视觉助力制造业转型升级,技术突破加速国产替代
根据美国自动化协会定义:机器视觉是光学、机械、电子、计算、软件等技术一体化的工业应用系统,其利用相机和计算机代替人的视觉感知和判断能力,自动采集并分析图象,以获取用于控制或评估特定活动所需的数据。主要由成像、信号分析与处理、决策与执行三个关键环节构成。功能上具体可以分为识别、测量、定位和检测四种。
在工业应用场景中,机器视觉相比人眼视觉在识别精确度、识别速度、环境要求、识别客观性、可靠性、工作效率、数据价值方面均存在显著优势,能够较好的替代人工进行工作。随着深度学习、3D视觉技术、高精度成像技术和机器视觉互联互通等技术的持续发展,机器视觉的性能优势将进一步扩大,应用场景也将持续拓展。同时,在人力成本日益增长的背景下,机器视觉在成本端上也具有明显优势,机器视觉也将助力企业实现降本增收。此外,通过机器视觉设备可以收集生产过程中的各种数据,进而推动工业互联网的发展进程。
工业机器视觉产业链上游为零部件及软件算法,是产业链中价值较高的部分,中游为视觉装备及方案,下游为具体的应用场景与行业。上游零部件主要包括光源(及其控制器)、工业镜头、工业相机及机器视觉软件算法。根据华经产业研究院数据,零部件及软件算法为机器视觉系统主要的成本来源,占比之和达到80%。组装集成和维护占比较少,分别占15%和5%。
随我国工业制造转型升级和数字化不断推进,工业机器视觉产业市场规模增长迅速。GGII数据显示,2021年中国机器视觉市场规模138.16亿元(未包含自动化集成设备规模),同比增长46.79%。其中,2D与3D视觉市场规模分别为126.65亿、11.51亿元。出于宏观经济回暖、新基建投资增加、制造业自动化等推进因素,根据GGII预测,2022至2025年,中国机器视觉市场规模同比增速维持在30%-40%之间,至2025年我国机器视觉市场规模将达到468.74亿元,市场潜力巨大。下游应用领域上,GGII数据显示,3C电子行业是工业机器视觉应用最多的下游领域;半导体、汽车、锂电池、食品饮料、物流仓储等行业亦为主要应用领域。

国产工业机器视觉企业在各自领域不断发展成熟,逐步实现国产替代。机器视觉海外龙头康耐视、基恩士均有较为完整的产业链布局,且技术实力领先,国产厂商则有所侧重,如精测电子和华兴源创主营视觉设备、奥普特从光源等核心硬件拓展核心零部件完整布局、凌云光基于软件算法能力发展可配置视觉系统、视觉设备业务。随着技术的不断成熟,国产厂商已在行业的细分领域中打破国外企业垄断,例如奥普特已成为光源的龙头企业,天准科技、矩子科技、凌云光已成为视觉系统及装备的头部厂商。整体上看,根据GGII数据显示,2021年国产品牌机器视觉市场份额占比58.43%,国产渗透率逐步提升。随着新能源、汽车电子及半导体等下游行业的扩产加速,工业机器视觉的国产化替代进程将进一步提速。
3.3.2全球EDA行业呈现寡头垄断格局,国产厂商迎来发展机遇期
EDA板块:增速稳定、高壁垒、高估值板块。1)增速稳定:EDA公司商业模式大多数为按年付费,一般收费在IC设计公司收入的1%-3%之间,占IC公司收入比重较低,并且EDA公司议价权较高,因此对于成熟稳定的客户,每年给EDA公司付费基本稳定或者略有增长,商业模式和高壁垒决定了EDA公司受下游需求波动影响较小。EDA行业增长一是受益于IC设计门槛降低,IC公司数量越来越多,二是IC品类不断拓张,比如第三代半导体的出现,三是伴随着先进制程迭代,产品复杂度提高带来的单价提升。加上盗版等因素的存在,实际上有部分需求并未体现在EDA公司收入中,通过盗版的不断转化,EDA龙头公司中长期均保持稳定增长。2)高壁垒;技术壁垒本身较高,需要强大的数学物理基础理论支撑,对算法要求很高。同时用户协同壁垒较高,制造、设计、EDA厂商三方形成稳定的生态圈,新进入者极难打破。因此,高壁垒以及良好的业务稳定性和成长性,使得EDA公司如新思科技、Cadence在美股半导体板块中估值一直相对较高。
EDA行业保持稳定增长,国内增速更快。根据赛迪数据,2020年全球EDA行业实现总销售额72.3亿美元,同比增长10.7%。预计至2024年,全球市场规模有望达到105亿美元,2020-2024年复合年均增长率为7.8%。2020年国内EDA市场规模为66.2亿,预计至2024年,我国EDA工具市场规模有望达到115亿元人民币,2020至2024年的市场规模符合年均增长率近17%。

EDA结合人工智能是趋势。EDA问题具有高维度、不连续、非线性和高阶交互的特性,机器学习等算法能够显著提高EDA的自主程度,提升IC设计效率,缩短研发周期。人工智能赋能EDA主要从Inside和Outside两方面实现,从Inside方面,通过机器学习对DRC、能耗、时序等预测,在参数模型建立过程中实现参数的优化,同时实现更高效的物理空间设计。Outside方面,通过机器学习方式,减少人工干预,极大释放劳动力。
EDA巨头积极进行人工智能与芯片设计的深度融合。EDA巨头Cadence发布了内嵌人工智能算法的Innovus,ProjectVirtus,SignoffTiming等工具,实现了全流程数字化智能化。Mentor通过机器学习OPC将光学邻近效应修正(OPC)输出预测精度提升到纳米级,同时将执行时间缩短3倍。Synopsys推出业界首个用于芯片设计的自主人工智能应用程序——DSO.aiTM。国产EDA产商迎来新战略机遇期。目前全球EDA工具上大约有近百家,排名前三的公司分别是新思科技(Synopsys)、铿腾电子(cadence)和明导(Mentor),三家巨头占据着全球近7成左右的市场份额,在中国的市占率更是超过95%。2022年8月生效的《2022芯片与科学法案》对EDA软件进行了出口管制,芯片核心技术自主可控势在必行,国产EDA厂商迎来重要的发展机遇。