打造分布式AI开发和部署平台,「潞晨科技」完成数亿元A轮融资
导读:潞晨科技宣布完成数亿元的A轮融资。据公司介绍,本轮融资是潞晨科技成立18个月内完成的第三轮融资,此次融资资金将主要用于团队扩张和业务拓展。
潞晨科技宣布完成数亿元的A轮融资。据公司介绍,本轮融资是潞晨科技成立18个月内完成的第三轮融资,此次融资资金将主要用于团队扩张和业务拓展。
众所周知,如今生成式AI的“涌现”能力来自于底层大模型的成熟,但训练大模型需要的算力、网络、数据成本非寻常公司能承受。而本文主角潞晨科技,希望为这一难题提供解法。
潞晨科技成立于2021年,主要业务是通过打造分布式AI开发和部署平台,帮助企业降低大模型的落地成本,提升训练、推理效率。公司创始人尤洋告诉36氪,自己此前在伯克利、新加坡国立大学均从事分布式计算、机器学习、高性能计算相关研究,曾创造ImageNet以及BERT训练速度的世界纪录。而在2021年左右,他更加笃信大模型的趋势,所以在当年创立潞晨科技,希望降低大模型的落地门槛。
潞晨科技当前的产品包括开源高效深度学习系统Colossal-AI和对应的企业版PaaS平台。平台主要由异构内存管理系统、高效N维并行系统、低延时推理系统组成,整体希望帮客户达成最小化模型部署成本、最大化计算效率的效果。
针对内存管理,尤洋对36氪表示,模型参数、层数越大,计算量相应也越大。GPT3的1750亿参数,可能需要占据800G内存。再加上训练神经网络时还需要存梯度、优化器状态,“GPT3在什么都没干的情况下,就要消耗3200G内存。”尤洋举例。再加上内存资源其实较为稀缺,所以科学管理内存资源在训练大模型的场景下变得异常重要。当GPU内存放不下这些数据,还需要把部分数据迁移到CPU、NVMe硬盘上。
尤洋表示,管理GPU、CPU、NVMe硬盘被称为异构管理。过去,异构管理主要延续静态思路,一开始就预估好参数、梯度、优化器等所需的资源。在尤洋看来,这种方式由于比较固化,没办法随着实际训练过程调配,很可能存在浪费资源。但潞晨采取的动态管理方式,可以更加灵活的平衡资源,“我们希望数据都能放到GPU里。但是如果GPU放不下了就放CPU里,CPU放不下就放NVMe里,但同时我们需要最小化CPU、GPU、NVMe之间的数据移动,这是最重要的。”尤洋表示,潞晨的异构内存管理系统可以帮助达成这一目标。
另一方面,企业如今训练大模型,常基于成百上千张GPU卡完成。这是因为,理论上,卡越多需要的训练时间越少,大模型的落地也更具效率。但实际情况中,卡越多意味着承载计算功能的机器越多,而在最终汇总各机器结果时,通信又会造成新的效率损耗。
针对这一痛点,潞晨打造了高效N维并行系统。尤洋表示,在这一系统中公司采用了高维张量并行等方式提升效率。尤洋表示,这背后的原理主要是用二维的方式设计张量并行。张量并行可以让计算任务被分解后同步进行。二维切片的方式,则让每个机器只需要和同行或者同列的机器打交道,不需要和所有机器打交道。“假如我们要1万个机器计算、传统方法(一维)一个机器需要跟9999个剩下机器打交道,我们只需要和99个机器打交道就可以。”他说。
第三是低延时推理系统,作用是减少模型推理速度慢带来的延时感。尤洋表示,解决这一问题,整体的部署方式和模型本身的优化都很重要。在优化方面,潞晨的内存管理、张量并行技术,以及剪枝蒸馏等方案均能发挥作用。
可以看出,异构内存管理系统、高效N维并行系统主要在训练步骤中发挥效力,低延时推理系统则提升推理部分的速度。若再细分,异构内存管理系统更能帮助客户节省资源成本,高效N维并行系统更能提升计算速度。尤洋表示,目前这三大系统均汇聚在公司的PaaS平台中,开源版本Colossal-AI目前也已获得约3万颗GitHub星星。在具体服务方式上,尤洋表示,目前客户可以通过潞晨的PaaS平台直接训练自己的模型,潞晨也可以帮助客户训练模型。据介绍,目前潞晨的方案已在自动驾驶、云计算、零售、医药、芯片、金融等行业落地。
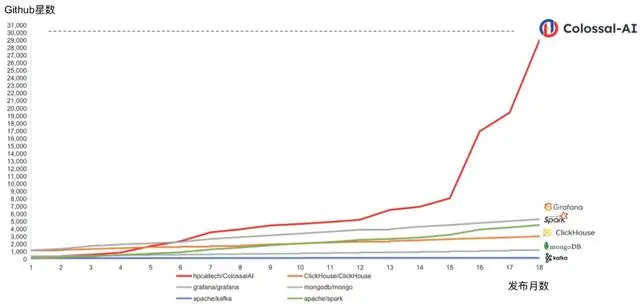
Colossal-AI GitHub星数
在2023年的整体规划上,尤洋告诉36氪,今年以来公司的业务量随着各行业客户的模型训练需求激增,预计收入整体相比去年会增长3-5倍。据了解,本轮融资后潞晨将加速扩张,并希望吸引招募更多的MLOps、AI大模型、AI框架等领域优秀人才加入,以更好服务客户。