数据标注:AI背后又一个鸡蛋悖论?
导读:在chatGPT掀起人工智能(AI)热潮的当下,AI三要素之一的数据也成为了热门话题。
在chatGPT掀起人工智能(AI)热潮的当下,AI三要素之一的数据也成为了热门话题。
作为AI大语言模型高质量回答的基础,训练数据生产过程主要包括四个环节:设计(训练数据集结构设计)、采集(获取原料数据)、加工(数据标注)及质检(各环节数据质量、加工质量检测)。其中,数据标注需要识别图像、文本、视频等原始数据,并添加一个或多个标签为机器学习模型指定上下文,帮助其做出准确的预测。
不过,数据标注是仍需要大量人工来完成的环节。“人工有多强大,智能才有多强大。”主营AI数据采集标注业务的杭州景联文科技副总裁刘云涛在接受第一财经采访时称,这还是一个先有鸡或先有蛋的故事。
但刘云涛同时表示,数据采集标注行业发展至今,已成为半人工智能、半人工化的行业。全栈AI数据及模型解决方案供应商倍赛科技创始人兼CEO杜霖也认为,数据标注本质上是一个研发密集型产业。
数据标注与大模型质量正相关
“当下的机器学习技术大部分依赖于human-in-the-loop,即有监督或来自人类反馈的学习。”杜霖在接受第一财经采访时表示,“而监督和反馈即人对数据的标注与评价。”
AI分析公司Cognilytica研究数据显示,在AI项目中,对数据相关的处理过程可占据超过80%的时间,其中数据标注环节的耗时占比可达25%。
数据标注是指对未经处理的语音、图片、文本、视频等数据进行转义、打点、拉线、拉框等操作,标注为电脑可以识别的信息,再上传到数据库,实现人工智能。一般来说,标注上传的数据越多、越准确,人工智能也就越智能。
招商证券表示,GPT-3与前一代产品GPT-2架构相同,但训练数据与参数量显著提升,GPT-2的预训练数据量为40GB、参数量仅有15亿个,而GPT-3的参数训练量达到45TB、参数量更是高达1750亿个,约有4900亿个tokens。从回答质量上看,ChatGPT回答内容比GPT-2更贴切、准确,并且符合人类语言习惯。
不过,杜霖认为,标注数据贵不在数量而在质量。
“从GPT的实验发现,随着模型参数量的增加,模型性能均得到不同程度的提高。但值得注意的是,通过来自人类反馈的强化学习(RLHF)生成的InstructGPT模型,比100倍参数规模无监督的GPT-3模型效果更好,也说明了有监督的标注数据是大模型应用成功的关键之一。”
如何提升数据标注的质量?刘云涛认为,一是提高标注准确率,二是提高贴合度。“以自动驾驶为例,红绿灯、车道线等标注准确度越高,算法精度就越高;贴合度从5个像素点变成1个像素点,算法精度也随之提升。”刘云涛表示,“此外,多维度也是提高质量的方式。比如chatGPT在面对一些问题时面对不同的人会有不同的答案。”
我国数据标注行业迅速发展
随着全球新一轮AI热潮来临,大量训练数据已成为AI算法模型发展和演进的“燃料”。
艾瑞咨询数据显示,包括数据采集、数据处理(标注)、数据存储、数据挖掘等模块在内的AI基础数据服务市场,将在未来数年内持续增长,到2025年,国内AI基础数据服务市场的整体规模预计将达到101.1亿元,整体市场增速将达到31.8%(2024-2025年)。
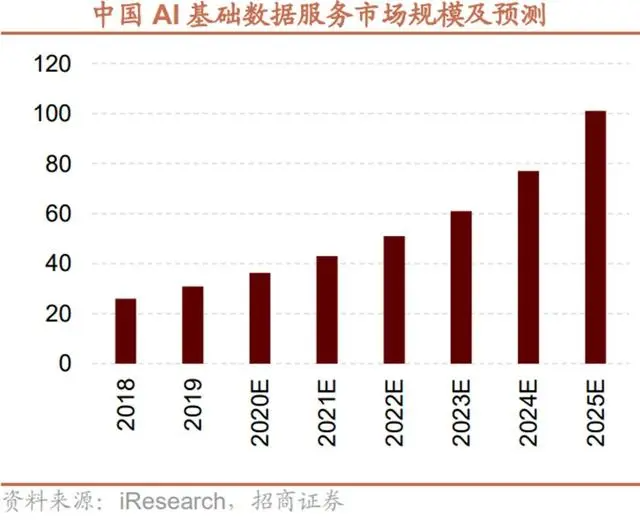
而据iResearch数据,2019年我国数据标注市场规模为30.9亿元,预计2025年市场规模突破100亿元,年复合增长率达到14.6%。
与此相伴随,中国数据标注行业正在迅速发展。招商证券认为,一方面,进入大数据时代后,人们各种行为的电子化、网络化带来海量数据,但产生的数据只有1%能被收集和保存,并且收集的数据中90%是非结构化的数据;另一方面,人工智能的兴起带来模型训练所用结构化数据的巨大需求,数据标注的重要性逐渐突显。
按照下游场景类型,2021年我国人工智能数据标注市场中,计算机视觉类、智能语音类和NLP类需求占比分别为45.3%、40.5%和14.2%。而AI基础数据及软件服务提供商龙猫数据相关人士告诉第一财经,随着数据量的不断增长和数据结构的不断变化,数据标注行业涉及的领域也越来越广泛,特别是在自动驾驶、AIGC等领域内,数据标注需求量极大。
刘云涛也持类似观点。“现在最大的需求点就是自动驾驶,目前数据采集标注这个行业内所有的公司都在围绕自动驾驶,未来5到10年的需求量还会越来越大。”
资料显示,国内AI训练数据提供商龙头海天瑞声(688787.SH)正在积极发力自动驾驶业务,该公司已于2022年6月上线第三代智能驾驶标注平台并发力研发第四代产品,截至2022年第三季度,海天瑞声已验收订单以及在手订单合计约5000万元,同比增长超200%。
AI大模型也将带来大量需求。刘云涛称,“预计今年10月国内会迎来一波大的类chatGPT大模型的数据需求,而且这是一个海量的需求,以目前国内几家头部数据标注公司来看,目前产能还不足以满足需求。”为此,景联文科技正加大对大模型方案的投入并深化相关业务。
AI背后:人工有多强大,智能才有多强大?
标注数据如同实现人工智能的一砖一瓦,对于数据采集标注企业来说,数据质量和经营效率无疑是最直接的竞争力,除了自研标注工具外,数据标注员的管理是重要抓手。
“当前,大部分数据标注任务仍然需要人工完成,而且各种数据类型和应用领域都需要相应领域的专业标注员来完成标注任务。”龙猫数据相关人士表示。
据悉,数据标注员是数据标注公司最核心的岗位之一,主要工作是借助标注工具,对人工智能学习数据进行加工,数据一般为图片、视频、文本等,通过不断地拉框、标点等操作,为人工智能提供足够的数据集。
此前,数据标注员的门槛较低,只需要细致有耐心;如今在一些高难度、高质量标准的标注任务中,标注员的素质对标注过程和结果的准确性和稳定性至关重要。例如,在自动驾驶、AIGC等数据类型的标注任务中,标注员需要有相应领域的专业知识和技能才能准确地标注数据。
龙猫数据相关人士表示,数据标注行业压力也很大,市场竞争激烈,标注公司为了保持竞争优势,需要投入更多的成本来吸引、留存、培养和管理标注员队伍,而这些额外的成本也增加了行业的人力密集型特征。
刘云涛也赞同上述观点,不过,他表示,数据采集标注行业发展至今,已成为半人工智能、半人工化的行业。
面对大语言模型动辄上百亿参数的数据质量控制,需要通过标注平台将一个个复杂RLHF需求拆成很多个简单的工作流,让机器去做预处理,人去做深层的基于理解的反馈,以减少人在简单问题上的精力消耗,专注在专业问题上的标注。杜霖介绍,“比如交叉验证模式,即通过人和机器混合验证的模式或者复检的模式,来进一步提升标注质量;此外一系列标准化任务培训的机制,以确保人类反馈的答案一致性,也都是通过平台来实现的。”
景联文也采用主动质检加被动质检的方式,前者靠人为去做质检,后者是靠算法去做一些预识别。“现在数据标注行业还是‘人工智能的背后,人工有多强大,智能才有多强大’。虽然有标注工具,但这还是一个先有鸡或先有蛋的故事。”刘云涛坦言。
据悉,目前数据标注工具的准确率部分仅百分之几,部分准确率则可以达到80%、90%。“机器标注的识别率越高,我们的人工需求就会越少,成本、利润、速度、质量都能更加可控。”刘云涛称。
杜霖认为,数据标注行业的核心是高效的人机交互工具和任务分发管理平台,“我们公司员工大部分都是围绕着我们平台来做研发和运营管理,真正的标注则通过赋能产能网络去完成。我们主要积累的技术是围绕在怎么通过工具和更高效的流程来实现自动化的任务拆解、预处理与匹配,所以我们是本质上是一个研发密集型公司,而不是一个劳动密集型公司。”
龙猫数据相关人士则称,随着技术不断发展,未来数据标注行业可能会实现更高的自动化程度,但应用领域不同,仍然需要一定数量的标注人员来进行标注任务。